
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- recordlock
- 특성화고졸재직자
- SpringSecurity
- 트랜잭션 격리수준
- Gabage Collection
- 분산트랜잭션
- Fetch Join
- Scale out
- pagnation
- sticky session
- transcation outbox
- 트랜잭션
- session clustering
- 일급컬렉션
- 특성화고졸재직자편입
- N+1
- 엔티티
- Shard
- 서비스장애
- 로드밸런서
- 전파옵션
- 분산 환경 세션 관리
- JPA
- Kafka
- cache
- outbox
- request collapsing
- Scale Up
- 특성화고졸재직자후기
- session storage
- Today
- Total
hwasowl.log
캐시, 동일 요청 최적화 방법 Request Collapsing 본문
https://github.com/Hwasowl/high-traffic-board
GitHub - Hwasowl/high-traffic-board: 대규모 데이터와 트래픽을 대응하는 게시판 시스템
대규모 데이터와 트래픽을 대응하는 게시판 시스템. Contribute to Hwasowl/high-traffic-board development by creating an account on GitHub.
github.com
실시간으로 게시글이 작성될 때 마다 데이터가 변하는 게시글 목록 데이터는, 어떻게 캐시를 적용할 수 있을까?
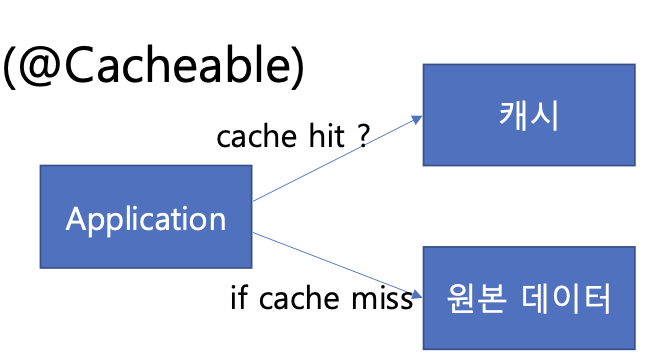
가장 일반적으로 적용할 수 있는 캐싱 기법이다.
1. 캐시에서 key를 기반으로 데이터 조회
2. 캐시 데이터 유무에 따라, 데이터가 있으면, 캐시의 데이터를 응답 데이터가 없으면, 원본 데이터를 가져오고, 캐시에 저장한 뒤 응답한다.
위 기법은 큰 문제가 없어 보이지만 허점이 있다.
@GetMapping("/v1/articles")
public ArticleReadPageResponse readAll(
@RequestParam("boardId") Long boardId,
@RequestParam("page") Long page,
@RequestParam("pageSize") Long pageSize
) {
return articleReadService.readAll(boardId, page, pageSize);
}
게시판 목록 데이터의 조회 파라미터는 boardId, page, pageSize 이다.
위 파라미터가 캐시의 키, 조회된 게시글 목록이 값이 될텐데, 단순히 키/값 저장 전략을 취하면 캐시 효과를 볼 수 있을까?
게시글이 작성/삭제된다면, 해당 키로 만들어진 게시글 목록은 과거의 데이터가 되어버린다. 또한 게시글 목록이 변경되어 있는데 목록 데이터는 key/value 고정 값으로 반영되어 있다.
즉 게시글이 작성/삭제될 때마다, 새로운 목록을 보여주려면 캐시만료가 필요하다.
그렇다고 캐시 만료를 임의로 늘린다면?캐시가 원본 데이터와 동기화 되어있지 않기 때문에, 과거 데이터가 노출된다.
최신 데이터를 반영하면서 캐시 히트율을 높일 수는 없을까?
캐시 데이터를 실시간으로 만들어서 미리 만들어둘 수도 있을 것 같다. 게시글이 생성/삭제되면, 캐시에 미리 목록 데이터를 생성해두는 것이다. 이미 카프카로 이벤트를 받고 있기 때문에 꽤 유효해 보인다. 하지만 레디스는 메모리 데이터이기 때문에 디스크에 비해 비싸다. 모든 데이터를 메모리에 저장해두기에는 현실적으로 어렵다.
그러면 모든 데이터를 캐시할 필요가 있을까?를 고민해보면 좋을 것 같다. 게시판의 사용 패턴을 알아보자
게시판의 사용 패턴은 어떨까?
특정 게시판을 클릭하면, 게시판의 첫 페이지로 이동하여 최신글 목록이 조회된다. 게시판의 첫 페이지에 나타나는 최신의 게시글이 가장 많이 조회될 수 밖에 없는 것이다. 뒷 페이지로 명시적으로 이동하지 않는 이상 과거 데이터는 비교적 조회 횟수가 적어진다. 즉, 모든 데이터를 캐시할 필요는 없다.
그렇다면 자주 조회되는 데이터에만 캐시를 적용해도 충분하지 않을까?
게시글 조회 서비스의 Redis는 최신 1000개의 목록만 캐시하고 1000개 이후의 데이터는 게시글 서비스로 요청해오는 전략을 취하면 좋을 것 같다.
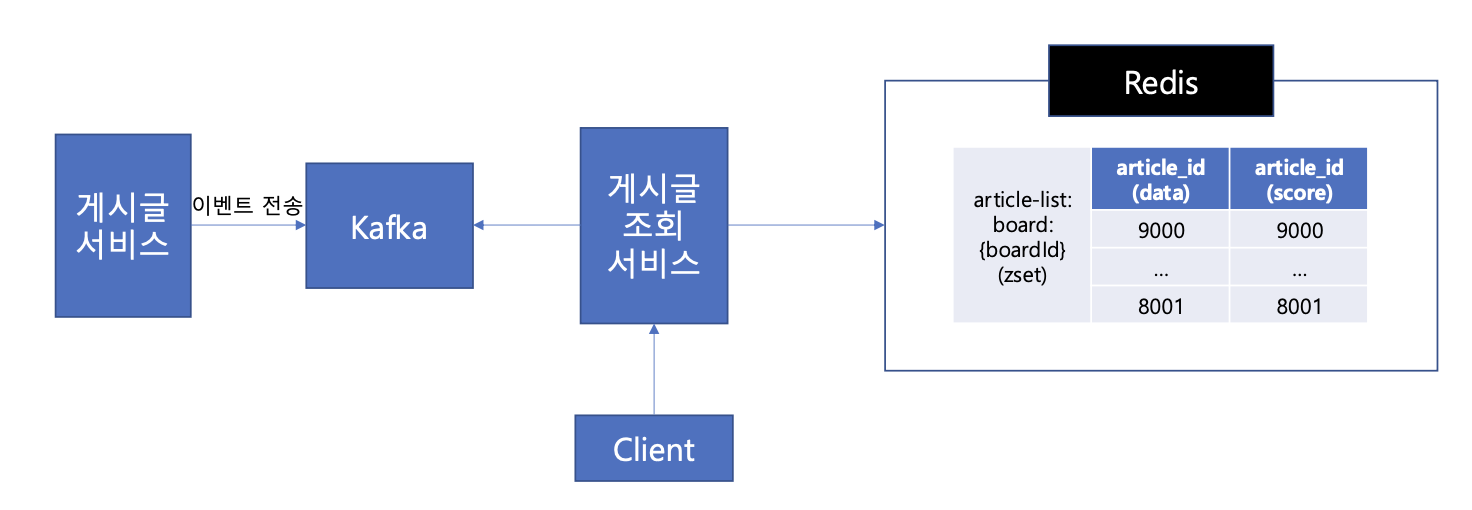
위 사진처럼 조회 서비스는 카프카로부터 전달 받은 게시글 생성/삭제 이벤트로, Redis에 게시판별 게시글 목록을 저장하고, sorted set 자료구조를 활용하여 최신순 정렬을 1000개까지 유지하게 설계했다.
이러면 Client가 게시글 목록을 요청했을 때 최신글 1000건 이내의 목록 데이터는 게시글 조회 서비스의 Redis에서 가져오고, 이후의 데이터는 게시글 서비스에서 가져올 수 있다.
큰 문제가 없어보이지만 동시에 많은 트래픽이 몰려오는 환경에서 효율적인지는 다시 생각해봐야한다.
다중으로 요청이 왔을 때 어떻게 처리되는지 알아보자
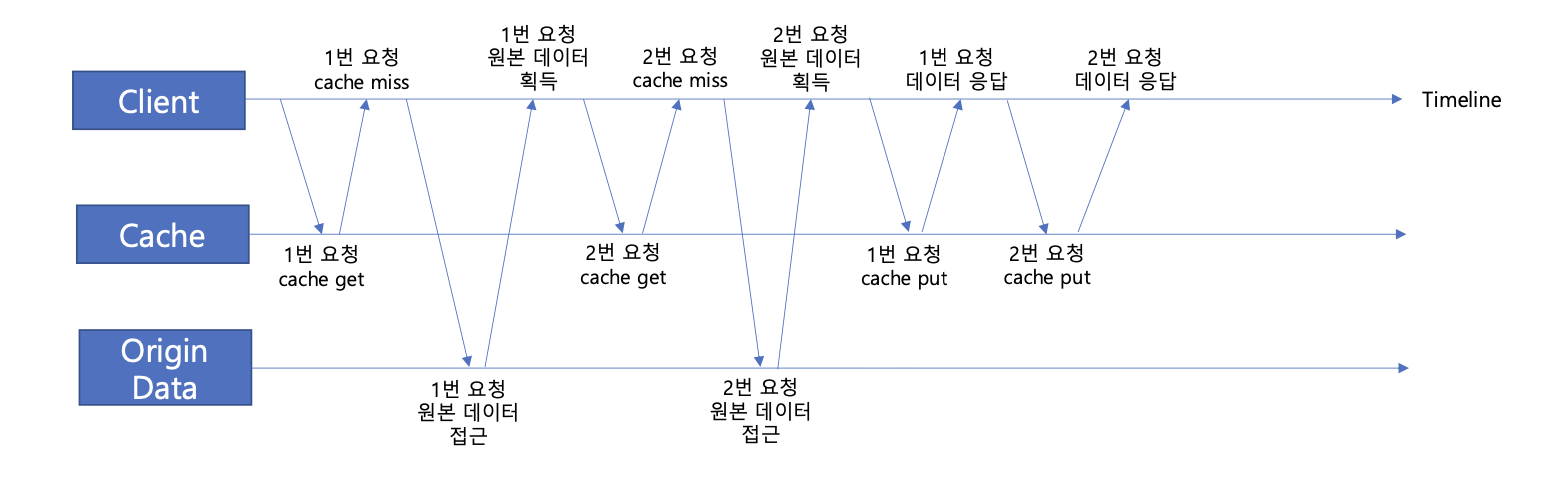
1번 요청이 왔을 때 캐시 미스로 인해 원본 데이터에 접근해 정보를 흭득했다. 하지만 2번 요청은 캐시가 적재되기 전에 요청했기에 캐시 미스로 또 다시 원본 데이터에 접근하고 있다. 문제점이 보이지 않는가?
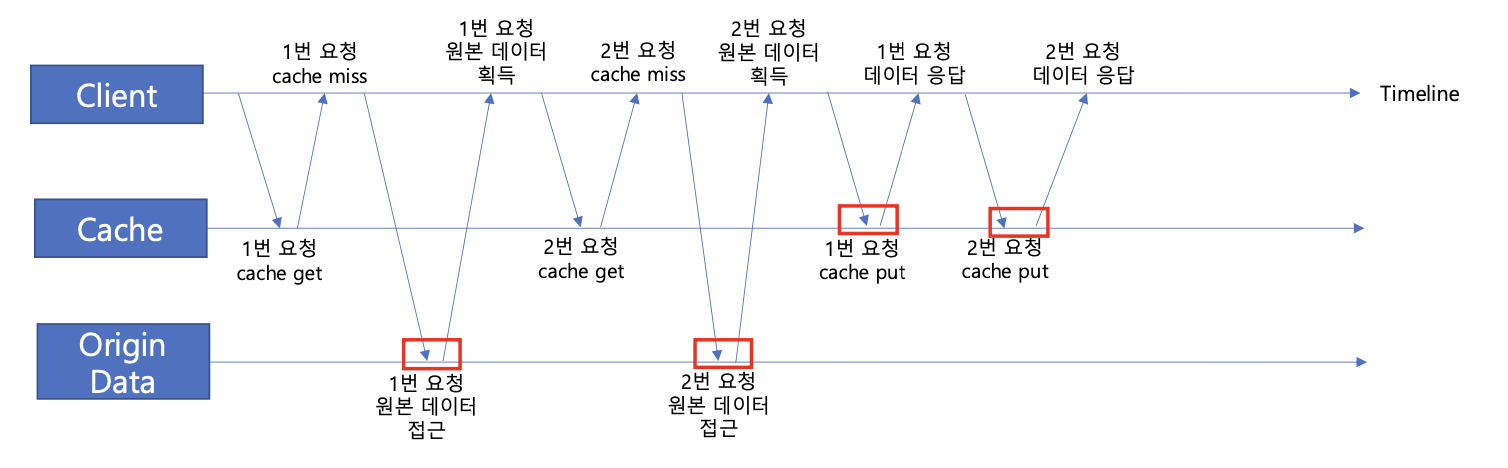
위 과정에서 원본 데이터에 접근하고 캐시에 데이터를 적재하는 과정은 두 번 수행됐다. 하지만 위 과정은 한 번으로도 충분했다. 동시 요청이 많다면, 원본 데이터에 접근하는 과정이 무의미하게 많아질 수 있는 것이다.
어떻게 이 문제를 해결할 수 있을까?
굳이 캐시 갱신을 기다리지 않고, 즉시 응답하면 되지 않을까? 데이터를 실제 만료로 설정된 시간보다 더 늦게 만료 시킨다면? 갱신을 위한 만료 시간(Logical TTL)과 실제 만료 시간(Physical TTL)을 다르게 가져가는 전략을 취해보자.
예를 들어, 사용자가 Logical TTL을 10초로 설정했다면, Physical TTL은 15초로 설정하는 것이다
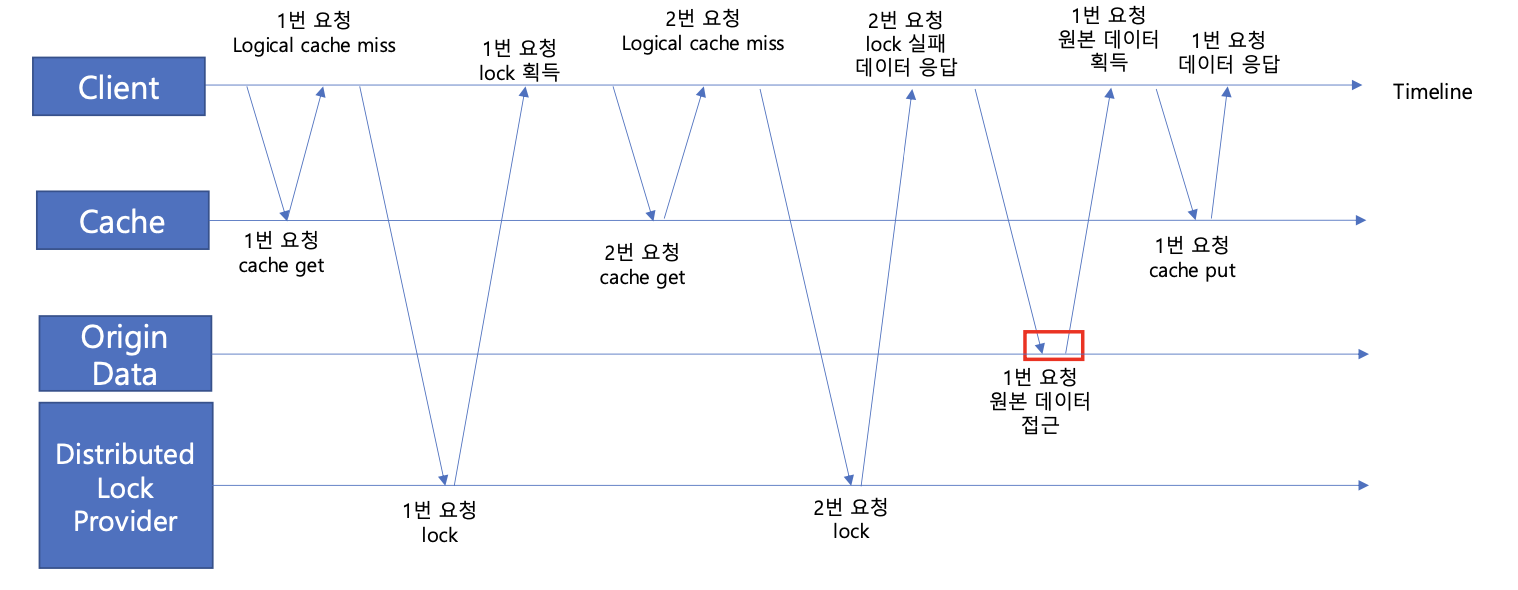
(캐시에 데이터가 있지만 논리적 TTL은 만료됐다고 가정한다.)
1. 1번 요청에서 캐시 get을 요청하지만 Logical TTL이 초과했기에 미스를 받고 락을 얻는다.
2. 2번 요청이 들어왔다. 하지만 1번 요청에서 이미 락을 획득 했으므로, 2번 요청은 락 획득에 실패한다.
3. 캐시에서 Logical TTL은 초과했지만, Physical TTL은 아직 초과되지 않아서 만료된 Logical TTL 데이터를 응답한다.
4. 1번 요청은 캐시를 갱신할 책임이 있으므로 원본 데이터에 접근 후 캐시를 저장하고 응답한다.
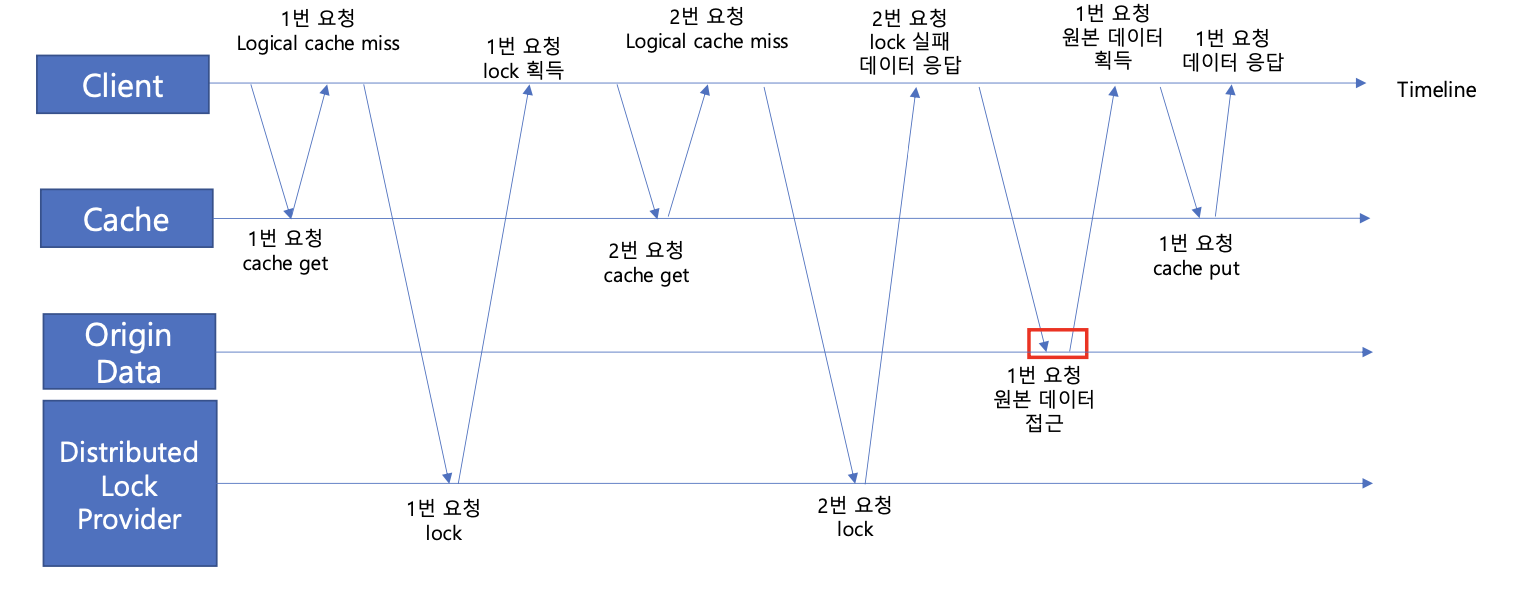
캐시 갱신에 대해 분산 락을 흭득함으로써 중복 수행을 방지한 것이다. 물론 Distributed Lock Provider로 락을 요청하는 과정이 추가되었지만, 원본 데이터를 다시 캐시에 적재하는 과정보다 훨씬 빠르게 수행될 수 있었다.
물론, 이러한 캐시 최적화 전략은 모든 경우에서 사용할 수는 없다. Logical TTL과 Physical TTL이 다르므로, 갱신이 처리 되기 전까지 과거 데이터가 일시적으로 노출될 수 있기 때문이다.
하지만 조회수와 같이 캐시 만료 시간이 아주 짧으면서 실시간 데이터 일관성이 반드시 중요하지 않은 작업, 또는 원본 데이터를 처리하는 게 아주 무거운 작업이면, 무의미할 수 있는 중복된 요청 트래픽을 줄임으로써 많은 이점을 가져올 수 있다.
또한 원본 데이터 서버에 부하를 줄이면서도, 캐시를 적극 활용하며 조회 성능을 최적화하는데 유리해질 수 있는 것이다. 이렇게 여러 개의 동일하거나 유사한 요청을 하나의 요청으로 병합하여 처리하는 기법을 Request Collapsing 이라고 한다.
'개인프로젝트' 카테고리의 다른 글
| 트랜잭션 전파 옵션 REQUIRES_NEW를 사용해 외부 API 호출을 효율적으로 관리하자 (1) | 2025.09.16 |
|---|---|
| 서비스 간 조회 최적화 방법 CQRS (0) | 2025.05.29 |
| Kafka Producer 설계 - Transactional Messaging, Transactional Outbox (0) | 2025.05.28 |
| 동시성 대응 방법 - 비동기 순차처리, 비관적&낙관적 락 (2) | 2025.05.24 |
| 조회 인덱스 최적화 방법 Covering Index (0) | 2025.05.02 |



