
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- SpringSecurity
- Scale Up
- N+1
- cache
- Fetch Join
- JPA
- 트랜잭션 격리수준
- transcation outbox
- 일급컬렉션
- sticky session
- Scale out
- 특성화고졸재직자
- 엔티티
- request collapsing
- 전파옵션
- Shard
- 분산 환경 세션 관리
- 트랜잭션
- 분산트랜잭션
- session clustering
- pagnation
- 로드밸런서
- outbox
- Gabage Collection
- Kafka
- 특성화고졸재직자후기
- 특성화고졸재직자편입
- session storage
- recordlock
- 서비스장애
- Today
- Total
hwasowl.log
조회 인덱스 최적화 방법 Covering Index 본문
https://github.com/Hwasowl/large-scale-design/tree/main/service/article
mysql> create table article (
-> article_id bigint not null primary key, // 샤드키
-> title varchar(100) not null,
-> content varchar(3000) not null,
-> board_id bigint not null,
-> writer_id bigint not null,
-> created_at datetime not null,
-> modified_at datetime not null
-> );mysql> select count(*) from article;
+----------+
| count(*) |
+----------+
| 7884001 |
+----------+
1 row in set (0.39 sec)
데이터 환경은 위와 같이 약 800만건으로 가정하겠다.
다뤄볼 article 테이블의 article_id는 auto increment 생성이 아닌 snowflake 알고리즘을 사용해 추가했다.
(간단하게 설명하면 멀티스레드 분산 환경에서의 동시성 문제를 해결하기 위함인데, 샤드키와 id 생성 관련한 건 따로 글을 작성하겠다.)
이 환경에서 limit offset 조회를 하면 어떻게 될까?
mysql> select * from article where board_id = 1 order by created_at desc limit 30 offset 90;
+--------------------+-----------+-------------+----------+-----------+---------------------+---------------------+
| article_id | title | content | board_id | writer_id | created_at | modified_at |
+--------------------+-----------+-------------+----------+-----------+---------------------+---------------------+
| 176562140552036593 | title5703 | content5703 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036594 | title5704 | content5704 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036595 | title5705 | content5705 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036596 | title5706 | content5706 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036597 | title5707 | content5707 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036598 | title5708 | content5708 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036599 | title5709 | content5709 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036600 | title5710 | content5710 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036601 | title5711 | content5711 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036602 | title5712 | content5712 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036603 | title5713 | content5713 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036604 | title5714 | content5714 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036605 | title5715 | content5715 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036606 | title5716 | content5716 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036607 | title5717 | content5717 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036608 | title5718 | content5718 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036609 | title5719 | content5719 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036610 | title5720 | content5720 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036611 | title5721 | content5721 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036612 | title5722 | content5722 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036613 | title5723 | content5723 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036614 | title5724 | content5724 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036615 | title5725 | content5725 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036616 | title5726 | content5726 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036617 | title5727 | content5727 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036618 | title5728 | content5728 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036619 | title5729 | content5729 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036647 | title5757 | content5757 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036645 | title5755 | content5755 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036646 | title5756 | content5756 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
+--------------------+-----------+-------------+----------+-----------+---------------------+---------------------+
30 rows in set (2.40 sec)
약 2.4초가 나온다. 정상적으로는 서비스 하기 힘든 수치이다.
오래 걸리는 이유는 무엇일까? 단순히 데이터 수량이 많아서?
mysql> explain select * from article where board_id = 1 order by created_at desc limit 30 offset 90;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
| 1 | SIMPLE | article | NULL | ALL | NULL | NULL | NULL | NULL | 8104364 | 10.00 | Using where; Using filesort |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+
1 row in set, 1 warning (0.01 sec)
explain으로 살펴보면 type이 ALL이다. 풀스캔 처리했고 데이터 수가 많아서 메모리가 아닌 filesort를 수행했다.
그렇다면 필요한 article_id, board_id에 대해서 인덱스를 추가하면 해결할 수 있을 것 같다.
mysql> create index idx_board_id_article_id on article(board_id asc,
-> article_id desc);
Query OK, 0 rows affected (16.68 sec)
Records: 0 Duplicates: 0 Warnings: 0
게시판id (board_id)에 대해서 오름차순 정렬, 게시글id (article_id)에 대해서 내림차순 정렬 인덱스를 만들었다.
[board_id=1, article_id=9], [board_id=1, article_id=8], [board_id=2, article_id=9], [board_id=2, article_id=8]
이런 식으로 잘 정렬이 되길 기대할 수 있고, 조회 속도도 빨라질 수 있을 것 같다.
mysql> select * from article where board_id = 1 order by article_id desc limit 30 offset 90;
+--------------------+-----------+-------------+----------+-----------+---------------------+---------------------+
| article_id | title | content | board_id | writer_id | created_at | modified_at |
+--------------------+-----------+-------------+----------+-----------+---------------------+---------------------+
| 176562140552036799 | title5909 | content5909 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036798 | title5908 | content5908 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036797 | title5907 | content5907 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036796 | title5906 | content5906 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036795 | title5905 | content5905 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036794 | title5904 | content5904 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036793 | title5903 | content5903 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036792 | title5902 | content5902 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036791 | title5901 | content5901 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036790 | title5900 | content5900 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036789 | title5899 | content5899 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036788 | title5898 | content5898 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036787 | title5897 | content5897 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036786 | title5896 | content5896 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036785 | title5895 | content5895 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036784 | title5894 | content5894 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036783 | title5893 | content5893 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036782 | title5892 | content5892 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036781 | title5891 | content5891 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036780 | title5890 | content5890 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036779 | title5889 | content5889 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036778 | title5888 | content5888 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036777 | title5887 | content5887 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036776 | title5886 | content5886 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036775 | title5885 | content5885 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036774 | title5884 | content5884 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036773 | title5883 | content5883 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036772 | title5882 | content5882 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036771 | title5881 | content5881 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
| 176562140552036770 | title5880 | content5880 | 1 | 1 | 2025-05-02 14:14:55 | 2025-05-02 14:14:55 |
+--------------------+-----------+-------------+----------+-----------+---------------------+---------------------+
30 rows in set (0.00 sec)0.00초로 조회 속도가 빨리진 걸 확인할 수 있다.
mysql> explain select * from article where board_id = 1 order by article_id desc limit 30 offset 90;
+----+-------------+---------+------------+------+-------------------------+-------------------------+---------+-------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-------------------------+-------------------------+---------+-------+---------+----------+-------+
| 1 | SIMPLE | article | NULL | ref | idx_board_id_article_id | idx_board_id_article_id | 8 | const | 4052182 | 100.00 | NULL |
+----+-------------+---------+------------+------+-------------------------+-------------------------+---------+-------+---------+----------+-------+
1 row in set, 1 warning (0.00 sec)
explain으로 key 부분을 살펴보면 인덱스를 사용해서 조회하고 있는 걸 확인할 수 있다.
근데 과연 이게 정답일까? 만약 수를 늘려 offset을 늘려본다면 어떤 일이 발생할까?
select * from article
where board_id = 1
order by article_id desc
limit 30 offset 1499970;
0.00초 걸리던 것이 갑자기 3.90초로 급격히 늘어났다.
왜 갑자기 이렇게 늘어났을까? 쿼리에서 변경된 것은 offset 뿐이다.
이 부분을 이해하려면 clustered index와 secondary index의 개념을 알아야 한다.
mysql의 기본 스토리지 엔진은 innoDB이다.
그리고 이 innoDB는 테이블마다 clustered index를 자동으로 생성한다.
- 정확히 규칙은 없지만 일반적으로 primary key에 자동으로 할당된다.
이 clustered index는 leaf node값으로 행 데이터를 가진다.
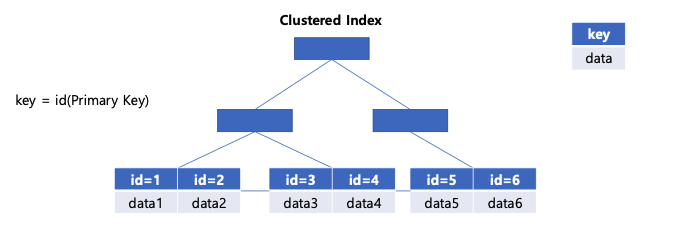
테이블을 추가하면 테이블에 primary key를 정렬 기준으로 하는 인덱스가 자동으로 생성된다.
이 leaf node에는 행 데이터를 가지고 있다. (row data)
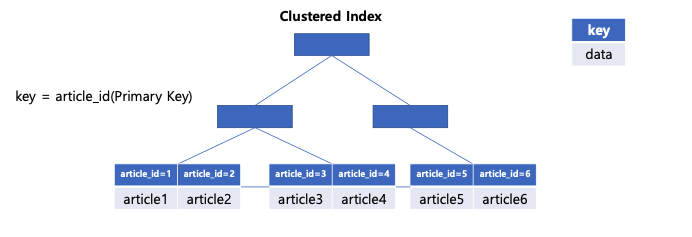
내가 설명하고 있는 article 테이블에는 article_id(게시글ID)를 기준으로 하는 clustered index가 생성되어있고 데이터를 가진다.
이 primary key를 이용한 조회는 자동으로 생성된 clustered index로 수행되는 것이다.
mysql> select * from article limit 1;
+--------------------+-------+------------+----------+-----------+---------------------+---------------------+
| article_id | title | content | board_id | writer_id | created_at | modified_at |
+--------------------+-------+------------+----------+-----------+---------------------+---------------------+
| 176249647565119488 | hi | my content | 1 | 1 | 2025-05-01 17:33:11 | 2025-05-01 17:33:11 |
+--------------------+-------+------------+----------+-----------+---------------------+---------------------+
1 row in set (0.01 sec)
mysql> explain select * from article where article_id = 176249647565119488
-> ;
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | article | NULL | const | PRIMARY | PRIMARY | 8 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
임의로 생성된 하나의 데이터를 하나 찝어서 조회해보면 key에 PRIMARY가 들어가있는 걸 확인할 수 있다.
별도로 인덱스를 추가하지 않았는데도 나오는 건 clustered index가 자동으로 사용된 것이다.
자 그러면 우리가 생성한 인덱스는 뭘까?
우리가 생성하는건 secondary index라고 한다. 흔히 보조 인덱스라고 부른다.
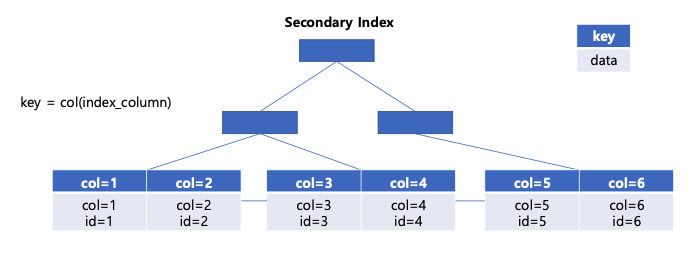
이 secondary index의 leaf node는 clustered index와 다르게 clustered index가 가지고 있는 데이터(row data)에 접근하기 위한 포인터와 인덱스 컬럼 데이터를 가지고 있다.
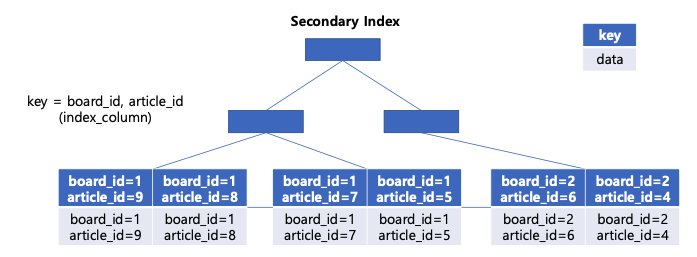
내가 실습하고 있는 환경에서는 이런 환경이다. article_id는 인덱스 컬럼 데이터이면서 데이터에 접근하기 위한 포인터이다.
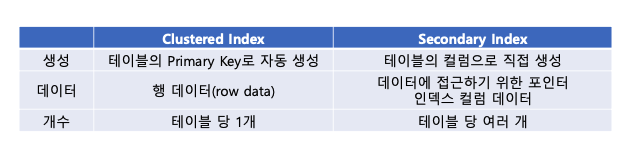
clustered index는 기본으로 primary key에 할당되고, 데이터로 행 데이터(row data)를 가지고 있다.
secondary index는 우리가 직접 생성하며 데이터로 clustered index 데이터에 접근하기 위한 포인터와 인덱스 컬럼 데이터를 가지고 있다.
그럼 secondary index를 이용한 조회는 어떻게 이뤄질까? 한다면
조회 요청 -> secondary index 에서 데이터 접근을 위한 포인터 id 확보 -> clustered index에서 데이터 조회.
총 인덱스 트리를 두 번 타서 조회한다.
그러면 다시 돌아와서 조회한 쿼리를 다시 살펴보자

우리는 이런 과정을 거쳐서 조회하고 있었다.

총 14499970 offset을 만날 때 까지 반복하며 skip하고 다 끝났다면

거기서 clustered index에 접근해 30개의 데이터를 limit으로 추출하고 있었다.
당연히 오래 걸릴 수 밖에 없는 방식의 연산이다.
이렇게 비효율적으로 무의미한 과정을 생략할 수는 없을까?
secondary index에서 필요한 30건에 대해서 article_id만 먼저 추출하고
그 30건에 대해서만 clustered index에 조회하면 매우 쾌적할 것 같은데 가능한 방법일까?
한번 시도해보자
mysql> select board_id, article_id from article where board_id = 1 order by article_id desc limit 30 offset 1499970;
+----------+--------------------+
| board_id | article_id |
+----------+--------------------+
| 1 | 176561295320088605 |
| 1 | 176561295320088604 |
| 1 | 176561295320088603 |
| 1 | 176561295320088602 |
| 1 | 176561295320088601 |
| 1 | 176561295320088600 |
| 1 | 176561295320088599 |
| 1 | 176561295320088598 |
| 1 | 176561295320088597 |
| 1 | 176561295320088596 |
| 1 | 176561295320088595 |
| 1 | 176561295320088594 |
| 1 | 176561295320088593 |
| 1 | 176561295320088592 |
| 1 | 176561295320088591 |
| 1 | 176561295320088590 |
| 1 | 176561295320088589 |
| 1 | 176561295320088588 |
| 1 | 176561295320088587 |
| 1 | 176561295320088586 |
| 1 | 176561295320088585 |
| 1 | 176561295320088584 |
| 1 | 176561295320088583 |
| 1 | 176561295320088582 |
| 1 | 176561295320088581 |
| 1 | 176561295320088580 |
| 1 | 176561295320088579 |
| 1 | 176561295320088578 |
| 1 | 176561295320088577 |
| 1 | 176561295320088576 |
+----------+--------------------+
30 rows in set (0.20 sec)
전체 데이터를 조회할 땐 약 4초가 걸렸는데
이제 board_id, article_id만 추출하는 것으로 0.2초가 소요됐다.
mysql> explain select board_id, article_id from article where board_id = 1 order by article_id desc limit 30 offset 1499970;
+----+-------------+---------+------------+------+-------------------------+-------------------------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-------------------------+-------------------------+---------+-------+---------+----------+-------------+
| 1 | SIMPLE | article | NULL | ref | idx_board_id_article_id | idx_board_id_article_id | 8 | const | 4052182 | 100.00 | Using index |
+----+-------------+---------+------------+------+-------------------------+-------------------------+---------+-------+---------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
explain을 보면 인덱스는 동일하게 사용되었지만 Extra에 using index가 추가되었다
이는 인덱스만 사용해서 데이터를 조회 했음을 의마한다.
이렇게 인덱스만 사용해서 데이터를 조회할 수 있는 인덱스를 covering index라고 한다.
이 covering index는 cluster index에 조회하지 않고 secondary index 정보만으로 쿼리 가능한 인덱스이다.
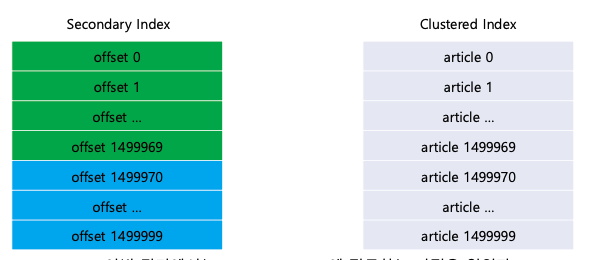
이번 조회에서는 clustered index에 아예 접근하지 않았다.
이 covering index로 얻은 id값으로 clustered index에 조회하면 될 것 같은데, 그럼 우리가 위에서 말한 말한 비효율적인 방식을 최적화 할 수 있을 것 같다.
mysql> select * from (select board_id, article_id from article where board_id = 1 order by article_id desc limit 30 offset 1499970) t left join article on t.article_id = article.article_id;
+----------+--------------------+--------------------+---------+-----------+----------+-----------+---------------------+---------------------+
| board_id | article_id | article_id | title | content | board_id | writer_id | created_at | modified_at |
+----------+--------------------+--------------------+---------+-----------+----------+-----------+---------------------+---------------------+
| 1 | 176561295320088605 | 176561295320088605 | title29 | content29 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088604 | 176561295320088604 | title28 | content28 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088603 | 176561295320088603 | title27 | content27 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088602 | 176561295320088602 | title26 | content26 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088601 | 176561295320088601 | title25 | content25 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088600 | 176561295320088600 | title24 | content24 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088599 | 176561295320088599 | title23 | content23 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088598 | 176561295320088598 | title22 | content22 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088597 | 176561295320088597 | title21 | content21 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088596 | 176561295320088596 | title20 | content20 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088595 | 176561295320088595 | title19 | content19 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088594 | 176561295320088594 | title18 | content18 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088593 | 176561295320088593 | title17 | content17 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088592 | 176561295320088592 | title16 | content16 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088591 | 176561295320088591 | title15 | content15 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088590 | 176561295320088590 | title14 | content14 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088589 | 176561295320088589 | title13 | content13 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088588 | 176561295320088588 | title12 | content12 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088587 | 176561295320088587 | title11 | content11 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088586 | 176561295320088586 | title10 | content10 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088585 | 176561295320088585 | title9 | content9 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088584 | 176561295320088584 | title8 | content8 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088583 | 176561295320088583 | title7 | content7 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088582 | 176561295320088582 | title6 | content6 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088581 | 176561295320088581 | title5 | content5 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088580 | 176561295320088580 | title4 | content4 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088579 | 176561295320088579 | title3 | content3 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088578 | 176561295320088578 | title2 | content2 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088577 | 176561295320088577 | title1 | content1 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
| 1 | 176561295320088576 | 176561295320088576 | title0 | content0 | 1 | 1 | 2025-05-02 14:11:33 | 2025-05-02 14:11:33 |
+----------+--------------------+--------------------+---------+-----------+----------+-----------+---------------------+---------------------+
30 rows in set (0.20 sec)
약 5,0000번 페이지에서 30개의 게시글을 추출하기 위해 약 4초 걸리던 쿼리가 0.2초로 개선되었다.

커버링 인덱스를 사용해서 미리 seconadary index에서 무의미한 데이터 접근 없이 1차로 가져온 후
그 가져온 데이터로 clustered index에 접근해 데이터를 빠르게 뽑아왔다.
mysql> explain select * from (select board_id, article_id from article where board_id = 1 order by article_id desc limit 30 offset 1499970) t left join article on t.article
_id = article.article_id;
+----+-------------+------------+------------+--------+-------------------------+-------------------------+---------+--------------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+-------------------------+-------------------------+---------+--------------+---------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 1500000 | 100.00 | NULL |
| 1 | PRIMARY | article | NULL | eq_ref | PRIMARY | PRIMARY | 8 | t.article_id | 1 | 100.00 | NULL |
| 2 | DERIVED | article | NULL | ref | idx_board_id_article_id | idx_board_id_article_id | 8 | const | 4052182 | 100.00 | Using index |
+----+-------------+------------+------------+--------+-------------------------+-------------------------+---------+--------------+---------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)
article_id 추출을 위한 서브쿼리 과정에서 파생 테이블(derived)가 생기지만
이 과정에서 커버링 인덱스가 사용되었다. 작은 규모의 파생 테이블과 조인해 30건에 대해서만 clustered index에서 가져오기에 빠르게 처리될 수 있었던 것이다!
하지만 정말 다 해결되었을까? 이제 5만번 페이지가 아닌 30만번 페이지를 조회해보자.


약 1.5초가 소요된다. 뒷 페이지로 갈 수록 느려지는 문제는 여전히 발생한다. 그 이유는 무엇일까
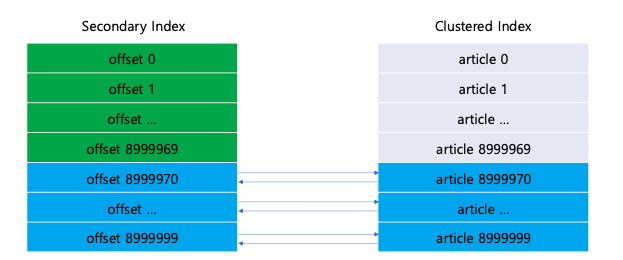
당연하게도 article_id 추출을 위해 세컨더리 인덱스만 탄다고 해도 offset 만큼 추출이 필요하다.
즉 clustered index 데이터에 접근하지 않더라도 offset이 늘어날 수록 느려질 수 밖에 없는 것이다.
해결 방법이 없는건 아니다. 데이터를 1년 단위로 분리하거나, offset 인덱스 페이지 단위로 skip하는 것이 아니라 1년동안 작성된 게시글 수 단위로 즉시 skip하는 방법 등등이 있다. (팀 상황에 맞게 적절한 방법을 찾아 분리하면 된다.)
근데 과연 30만번 페이지를 조회하는게 정상적인 케이스일까 고민하고 의심해봐야한다. (어뷰징 등등?)
시간 범위 페이지네이션을 제공하거나 정책으로 풀어내는 방법도 있다.
결론
데이터 수가 많은 환경에서는 covering index로 secondary index의 데이터를 단독으로 뽑아내고 clustered index에 조인해서 가져오는 것이 성능적으로 큰 이점을 가진다.
하지만 covering index도 조회의 성질을 가진다. 즉 인덱스 트리가 두 번에서 한 번으로 줄어든 것의 이점을 얻은 것이지 데이터 수가 많아졌을 때는 별도의 방법이 필요하다.
그 방법은 여러가지가 있다. 데이터베이스를 일정 단위로 분리하거나 비즈니스 로직을 추가해 데이터 수량을 줄여 covering index의 이점을 살리게 할 수 있다.
'개인프로젝트' 카테고리의 다른 글
| 트랜잭션 전파 옵션 REQUIRES_NEW를 사용해 외부 API 호출을 효율적으로 관리하자 (1) | 2025.09.16 |
|---|---|
| 캐시, 동일 요청 최적화 방법 Request Collapsing (0) | 2025.05.30 |
| 서비스 간 조회 최적화 방법 CQRS (0) | 2025.05.29 |
| Kafka Producer 설계 - Transactional Messaging, Transactional Outbox (0) | 2025.05.28 |
| 동시성 대응 방법 - 비동기 순차처리, 비관적&낙관적 락 (2) | 2025.05.24 |



