
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- N+1
- 트랜잭션
- JPA
- Shard
- 엔티티
- Kafka
- pagnation
- request collapsing
- 특성화고졸재직자후기
- sticky session
- 분산트랜잭션
- 일급컬렉션
- session clustering
- 특성화고졸재직자
- Fetch Join
- Scale Up
- Scale out
- 전파옵션
- Gabage Collection
- 서비스장애
- 트랜잭션 격리수준
- transcation outbox
- 특성화고졸재직자편입
- recordlock
- session storage
- outbox
- 분산 환경 세션 관리
- 로드밸런서
- cache
- SpringSecurity
- Today
- Total
hwasowl.log
Kafka Producer 설계 - Transactional Messaging, Transactional Outbox 본문
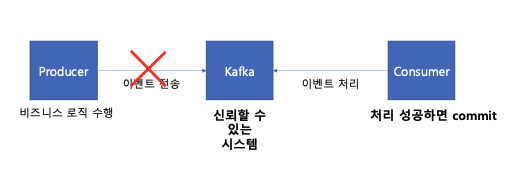
프로듀서가 카프카에게 이벤트 발행 도중 장애가 발생한다면 어떤 일이 발생할까? 카프카의 모든 브로커 장애가 발생했을 수도, 네트워크 순단일 수도 있다.
Producer는 Kafka로의 데이터 전송과 무관하게 정상 동작해야 한다. Kafka로 데이터 전송이 실패한다고 해서, Producer에 장애가 전파되면 안되는 것이다. 이로 인해 위와 같은 상황에서는, 게시글은 정상 생성되었더라도, 이러한 이벤트를 Kafka에 전달할 수 없는 상황이다.
신뢰할 수 있는 시스템인 Kafka로 아직 데이터가 전송되지 못했기 때문에, Producer가 생산 및 전파해야 하는 이벤트 데이터는 유실될 수 밖에 없다. 이로 인해 각 서비스마다 데이터의 일관성이 깨지게 된다. Producer에서 게시글이 생성되었는데, Consumer에서 게시글 생성 사실을 전달 받지 못하는 상황이 되는 것이다.
이를 해결하려면? 비즈니스 로직 수행과 이벤트 전송이 하나의 트랜잭션으로 처리되어야 한다. (비즈니스 로직 수행과 이벤트 전송이 모두 일어나거나, 모두 일어나지 않거나)
이러한 보장은 꼭 실시간으로 처리될 필요는 없다. 비즈니스 로직은 우선적으로 처리되더라도, 이벤트 전송은 장애가 해소된 이후 뒤늦게 처리되어도 충분할 수 있다. 최종적으로 일관성이 유지될 수도 있는 것이다.(결과적 일관성 Eventually Consistency)
그렇다면 Producer의 비즈니스 로직과 Kafka로의 이벤트 전송을 어떻게 하나의 트랜잭션으로 관리할 수 있을까?
일반적인 트랜잭션의 처리 과정을 살펴보자.

이러한 트랜잭션은, 스프링의 @Transactional을 이용하여 손쉽게 적용할 수 있었다.
단순하게 이벤트 전송 코드를 트랜잭션에 포함시키면 충분할까?

트랜잭션 범위 내에서 비즈니스 로직을 처리한 뒤에 이벤트를 Kafka로 전송해본다. 얼핏 보기에는 별 문제 없어 보인다.
하지만 위 코드에는 문제가 있다. 지금까지 사용하던 트랜잭션은, MySQL의 단일 데이터베이스(1개의 샤드)에 대한 트랜잭션인 것이다.
MySQL의 상태 변경과 Kafka로의 데이터 전송을, MySQL의 트랜잭션 기능을 이용해서 단일 트랜잭션으로 묶을 수 없는 것이다. MySQL과 Kafka는 서로 다른 시스템이기 때문이다.
물론, 3번 과정이 정상적으로 처리된 뒤에 트랜잭션을 종료할 수도 있다. 하지만, 만약 이벤트 전송 작업이 Kafka 장애로 인해 3초 동안 블로킹 된다면? 3초 동안 트랜잭션을 점유하고 있기 때문에, Kafka의 장애가 서버 애플리케이션과 MySQL로 장애가 전파될 수도 있다. 또는, 트랜잭션 commit이 실패했는데, 이벤트 전송은 이미 완료 됐을 수 있다.
3번 과정을 비동기로 처리한다고 해도? MySQL의 트랜잭션이 자동으로 롤백 되진 않는다. 롤백을 위한 보상 트랜잭션을 직접 수행할 수도 있겠지만, 이것도 누락될 수 있으니 문제는 더욱 복잡해진다.
그렇다면 2개의 다른 시스템을 어떻게 단일한 트랜잭션으로 묶을 수 있을까?
Transactional Messaging을 달성하기 위한 분산 트랜잭션의 몇가지 방법을 살펴보자.
- Two Phase Commit
- Transactional Outbox
- Transaction Log Tailing
Two Phase Commit
분산 시스템에서 모든 시스템이 하나의 트랜잭션을 수행할 때, 모든 시스템이 성공적으로 작업을 완료하면, 트랜잭션 commit, 하나라도 실패하면 트랜잭션 rollback한다. 이름에서 알 수 있듯이, 두 단계로 나뉘어 수행된다.
- Prepare phase(준비 단계)
Coordinator는 각 참여자에게 트랜잭션을 커밋할 준비가 되었는지 물어본다. 각 참여자는 트랜잭션을 커밋할 준비가 되었는지 응답한다.
- Commit phase(커밋 단계)
모든 참여자가 준비 완료 응답을 보내면, Coordinator는 모든 참여자에게 트랜잭션 커밋을 요청하고, 모든 참여자는 트랜잭션을 커밋한다.
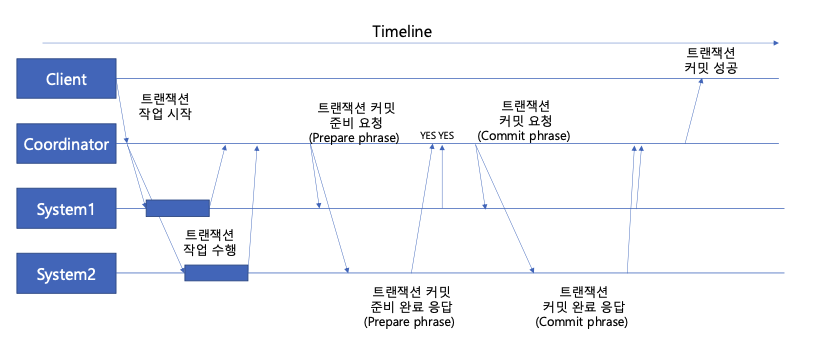
Two Phase Commit은 이러한 방법으로 분산 트랜잭션을 지원한다. 하지만, 몇 가지 문제 사항이 남아있다.
1. 모든 참여자의 응답을 기다려야 하기 때문에 지연이 길어질 수 있다.
2. Coordinator 또는 참여자 장애가 발생하면, 참여자들은 현재 상태를 모른 채 대기해야 할 수도 있다. 또한 트랜잭션 복구 처리가 복잡해질 수 있다.
문제 사항을 보면 성능 및 오류 처리의 복잡성 문제가 여전히 남아있다. 우리의 시스템은 Kafka와 MySQL 작업을 트랜잭션으로 처리해야 한다. 하지만 Kafka와 MySQL은 자체적으로 이러한 방식의 트랜잭션 통합을 지원하지 않는다.
결론적으로 Two Phase Commit은 Transactional Messaging을 달성하기에 적절하지 않다.
Transactional Outbox
이벤트 전송 작업을 일반적인 데이터베이스 트랜잭션에 포함시킬 수는 없다. 하지만, 이벤트 전송 정보를 데이터베이스 트랜잭션에 포함하여 기록할 수는 있다. 트랜잭션을 지원하는 데이터베이스에 Outbox 테이블을 생성하고, 서비스 로직 수행과 Outbox 테이블 이벤트 메시지 기록을 단일 트랜잭션으로 묶는다.

트랜잭션에서 비즈니스 로직이 잘 수행되면 이벤트 데이터를 Outbox 테이블에 저장하고, 다른 시스템에서 Outbox 테이블에서 미전송 이벤트를 조회해서 카프카에게 전송한다. 전송이 완료되었다면 완료 처리로 상태를 변경한다.
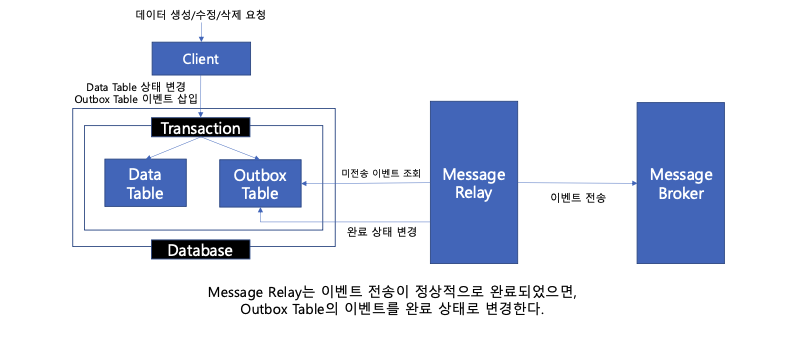
확실히 Two Phase Commit의 성능과 오류 처리에 대한 문제가 줄어든다. (데이터 유실X, 트랜잭션 블로킹 X)
데이터베이스 트랜잭션 커밋이 완료되었다면, Outbox 테이블에 이벤트 정보가 함께 기록되었기 때문에, 이벤트가 유실되지 않는다. 하지만 추가적인 Outbox 테이블 생성 및 관리가 필요하고, Outbox 테이블의 미전송 이벤트를 Message Broker로 전송하는 작업이 필요하다.
그렇다면, Message Broker로 이벤트를 전송하는 작업은 어떻게 할 수 있을까? 이벤트 전송 작업을 처리하기 위한 시스템을 직접 구축해볼 수 있고, Transaction Log Tailing Pattern을 활용할 수도 있다.
Transaction Log Tailing
데이터베이스의 트랜잭션 로그를 추적 및 분석하는 방법이다. 데이터베이스는 각 트랜잭션의 변경 사항을 로그로 기록한다. (binlog 등)
이러한 로그를 CDC(데이터 변경 캡쳐)를 활용해 읽어서 Message Broker에 이벤트를 전송해볼 수 있다.
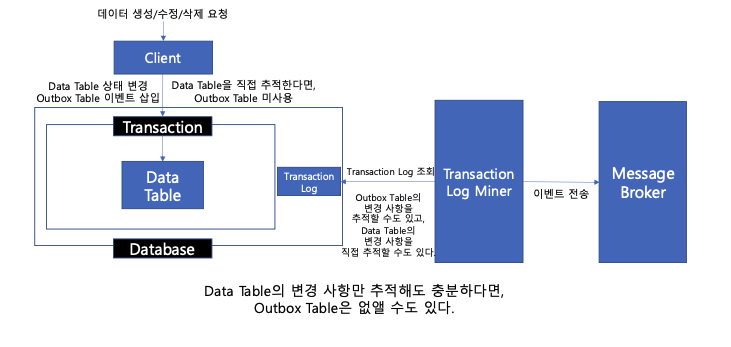
데이터베이스에 저장된 트랜잭션 로그를 기반으로, Message Broker로의 이벤트 전송 작업을 구축하기 위한 방법으로 활용될 수 있다. Data Table을 직접 추적하면, Outbox Table은 미사용 할 수도 있다. 하지만 트랜잭션 로그를 추적하기 위해 CDC 기술을 활용해야 한다.
지금까지 Transactional Messaging을 달성하기 위한 방법을 살펴보았는데, 어떤 방법을 채택할 수 있을까?
- Two Phase Commit
지연, 성능 문제, 오류 처리 및 구현의 복잡성, Kafka와 MySQL 통합의 어려움
- Transactional Outbox / Transaction Log Tailing
Two Phase Commit의 문제가 어느 정도 해결된다.
결론적으로 Transactional Outbox를 채택할 것이다.
Transaction Log Tailing을 활용하면 Data Table의 변경 사항을 직접 추적할 수 있다. Outbox Table이 필요하지 않을 수 있다. 하지만, Data Table은 메시지 정보가 데이터베이스 변경 사항에 종속된 구조로 한정 되버리고 만다. 하지만 Outbox Table을 활용하면, 부가적인 테이블로 인한 복잡도 및 관리 비용은 늘어나지만, 이벤트 정보를 더욱 구체적이고 명확하게 정의할 수 있다. 따라서 Outbox Table을 활용한다.
Transactional Outbox
데이터의 변경 사항과 Outbox Table로의 이벤트 데이터 기록을 MySQL의 단일 트랜잭션으로 처리한다.
이벤트 전송이 필요한 Article, Comment, Like, View 서비스는 트랜잭션을 지 원하는 MySQL을 사용하고 있기 때문에, Outbox 테이블과 트랜잭션을 통합하여 구현할 수 있다. Message Broker로의 전송은 스프링부트에서 직접 개발하고 처리한다.
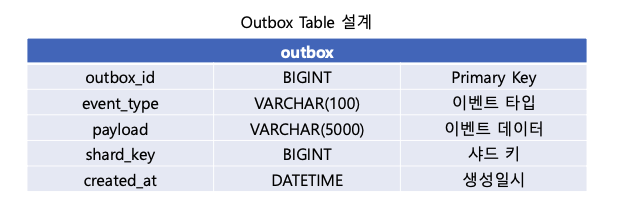
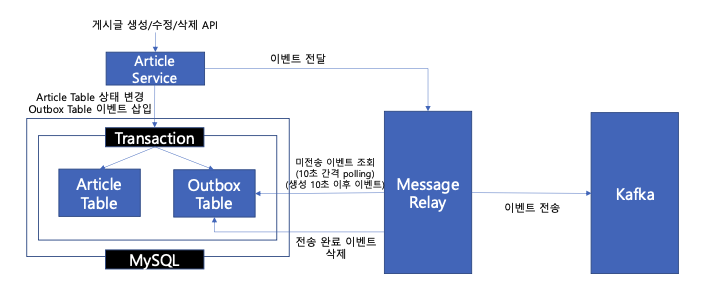
게시글 서비스는 비즈니스 로직을 수행하면서, Article Table 상태 변경과 Outbox Table 이벤트 기록을 단일 트랜잭션으로 처리한다.
Message Relay는 Outbox Table에서 미전송 데이터를 주기적으로 polling하여 조회하고, Kafka로 전송한다. 게시글 서비스에서 트랜잭션이 commit 되면, Message Relay로 이벤트를 즉시 전달한다. (릴레이는 전달 받은 이벤트를 비동기로 카프카에게 전송할 수 있다.)
이때 실패한 이벤트는 장애 상황에만 발생할 것이고, 정상 상황에서는 10초 정도면 이벤트 전송할 시간으로 충분 했을 것이다. 생성된 지 10초가 지난 이벤트만 polling 하자. 물론, 여전히 이벤트는 중복 처리될 수 있으므로 Consumer 측에서 멱등성을 고려한 개발은 필요하다.
-
릴레이에서 미전송 이벤트를 polling하는 것은 특정한 샤드 키가 없으므로, 모든 샤드에서 직접 polling해야 한다.
모든 애플리케이션이 동시에 polling 하면, 동일한 이벤트를 중복으로 처리할 수도 있고, 각 애플리케이션마다 모든 샤드를 polling 하면, 처리에 지연이 생길 수 있다. 각 애플리케이션이 처리할 샤드를 중복 없이 적절히 분산할 필요가 있다.
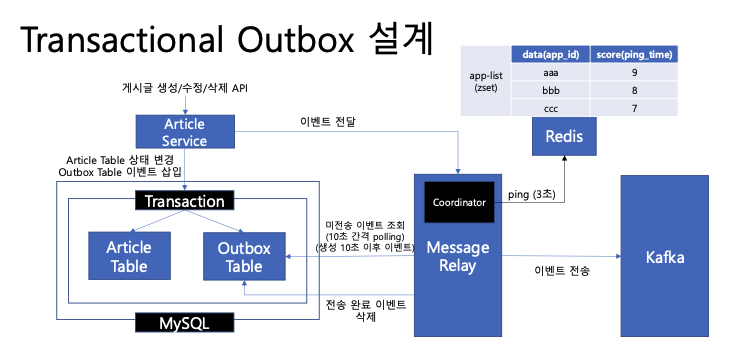
Coordinator는 자신을 실행한 애플리케이션의 식별자와 현재 시간으로, 중앙 저장소에 3초 간격으로 ping을 보낸다.
이를 통해 Coordinator는 실행 중인 애플리케이션 목록을 파악하고, 각 애플리케이션에 샤드를 적절히 분산한다.
중앙 저장소는 마지막 ping을 받은지 9초가 지났으면 애플리케이션이 종료되었다고 판단하고 목록에서 제거한다.
중앙 저장소는 Redis의 Sorted Set을 이용한다. 애플리케이션의 식별자와 마지막 ping 시간을 정렬된 상태로 저장해둘 수 있다.
Coordinator는 N개의 애플리케이션에 4개의 샤드를 범위 기반(Range-Based)으로 할당한다. 예를 들어, 2개의 애플리케이션이 있다면, 0~1번 샤드와 2~3번 샤드를 각각 polling 한다. 이처럼 범위를 지정해 분산하면 중복 처리 및 지연 문제를 해소할 수 있다.
'개인프로젝트' 카테고리의 다른 글
| 트랜잭션 전파 옵션 REQUIRES_NEW를 사용해 외부 API 호출을 효율적으로 관리하자 (1) | 2025.09.16 |
|---|---|
| 캐시, 동일 요청 최적화 방법 Request Collapsing (0) | 2025.05.30 |
| 서비스 간 조회 최적화 방법 CQRS (0) | 2025.05.29 |
| 동시성 대응 방법 - 비동기 순차처리, 비관적&낙관적 락 (2) | 2025.05.24 |
| 조회 인덱스 최적화 방법 Covering Index (0) | 2025.05.02 |



