
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 특성화고졸재직자
- Kafka
- 트랜잭션
- Shard
- 분산트랜잭션
- recordlock
- session clustering
- 로드밸런서
- 특성화고졸재직자후기
- 트랜잭션 격리수준
- request collapsing
- 일급컬렉션
- 분산 환경 세션 관리
- Fetch Join
- Scale out
- Gabage Collection
- 서비스장애
- outbox
- 전파옵션
- transcation outbox
- 특성화고졸재직자편입
- session storage
- 엔티티
- sticky session
- Scale Up
- N+1
- pagnation
- cache
- JPA
- SpringSecurity
- Today
- Total
hwasowl.log
서비스 간 조회 최적화 방법 CQRS 본문
https://github.com/Hwasowl/high-traffic-board
GitHub - Hwasowl/high-traffic-board: 대규모 데이터와 트래픽을 대응하는 게시판 시스템
대규모 데이터와 트래픽을 대응하는 게시판 시스템. Contribute to Hwasowl/high-traffic-board development by creating an account on GitHub.
github.com
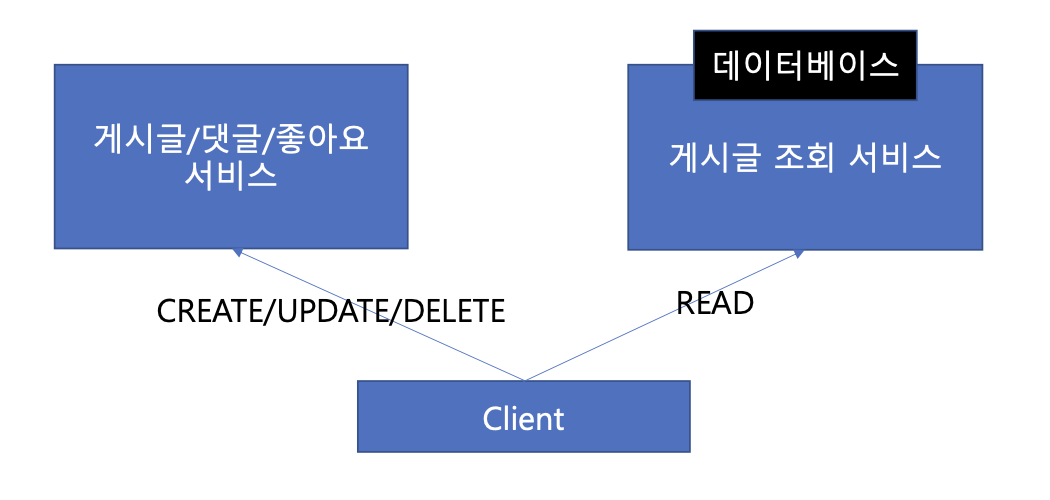
게시글 서비스 특성 상, 읽기 트래픽이 쓰기 트래픽보다 압도적으로 많다. 그리고 사용자에게 게시글만 보여주는 것이 아닌 좋아요 수, 댓글 수, 조회 수, 작성자 정보를 언제나 함께 보여줄 수 있어야 한다.
그렇다면 각 데이터가 분산되어 있는 환경에서 클라이언트는 어떻게 조회될 수 있을까?
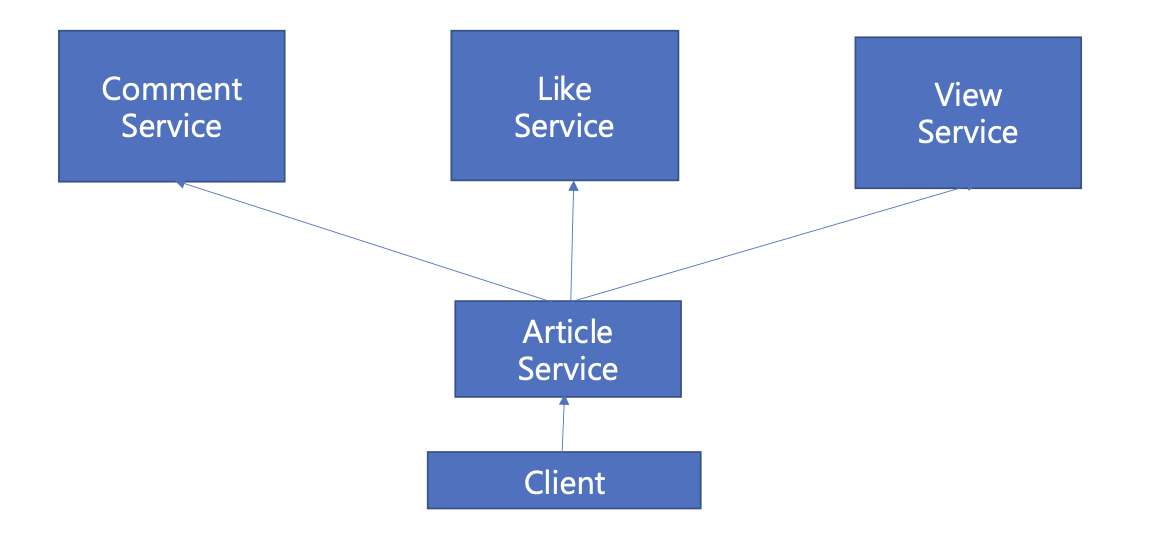
Client는 Article Service로 게시글을 요청하고, Article Service는 Comment/Like/View Service로 데이터를 요청하여, 애플리케이션에서 조인된 데이터를 응답해줄 수도 있다. 결국 조회되는 주체는 게시글이기 때문에, 위 구조도 얼핏 보기에는 별 문제 없어보일지도 모른다. 하지만 위 구조는 몇 가지 문제점을 가지고 있다. 하나씩 살펴보도록 하자.
1.
Article Service는 게시글 읽기와 쓰기가 모두 함께 처리된다. 하지만 게시판 서비스 특성 상, 읽기 트래픽이 쓰기 트래픽보다 압도적으로 많을 수 있다. 하지만 읽기 트래픽으로 인해 서버를 증설해야하는 상황이 온다면? 이 때, 쓰기 트래픽은 별다른 변화가 없는 상황일 수 있다.
하지만 읽기 트래픽으로 인해 서버를 증설함으로써, 쓰기 작업에 대한 리소스도 함께 확장될 수 밖에 없다.
읽기/쓰기 작업 특성에 의해 리소스가 낭비되는 지점이 생기는 것이다. 다른 문제도 살펴보자.
2.
이제까지 Article Service는 Comment/Like/View Service에 대해 의존성이 없었다. 하지만 게시글 조회 요구사항으로 인해 각 서비스에 의존성이 생길 수 밖에 없는 상황이다. 위 그림에서는 단방향으로 나타나지만, 정말 단방향일까?
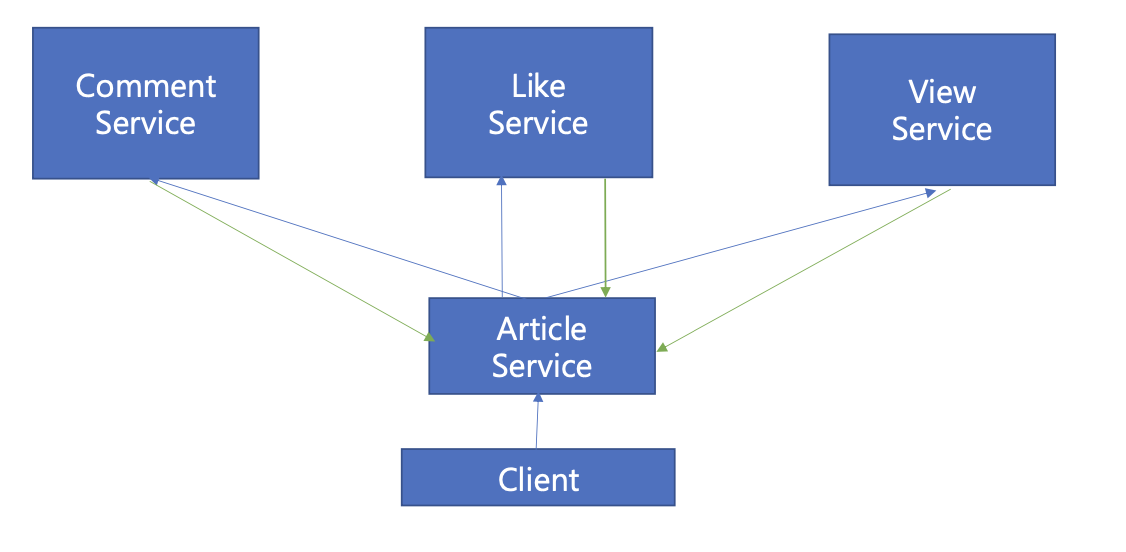
하지만 실제로는 각 Service와 Article Service 간에는 양방향 참조가 이루어지고 있다. 각 마이크로서비스 간에 순환 참조가 발생하는 구조인 것이다.
-
Comment/Like/View 참조키로 Article의 정보를 가지고 있다.(FK=articleId) 지금까지 개발을 진행하면서 데이터 검증 등에 대해 직접적으로 신경쓰진 않았지만, 각 Service는 데이터의 무결성을 검증하기 위해, 게시글 유효성 확인은 필요하다.
Comment/Like/View Service는 데이터의 무결성을 검증하려면, 게시글에 종속된 데이터이기 때문에 Article Service로 게시글 데이터 요청이 필요하다. 따라서, 단순히 Article Service가 각 서비스에 데이터를 요청하여 조합하면, 마이크로서비스 간에 순환 참조가 발생하게 되는 것이다. (의존성을 가지고 있는 것)
순환 참조로 인한 문제는 다양하고 치명적이다. 각 마이크로서비스는 독립적으로 배포 및 유지보수 될 수 없고, 서로 간에 장애가 전파될 수 있으며, 테스트에도 어려움이 생길 수 있다.
그렇다면, 위 문제들을 해결하면서 게시글 조회를 처리하려면 어떻게 처리할 수 있을까?
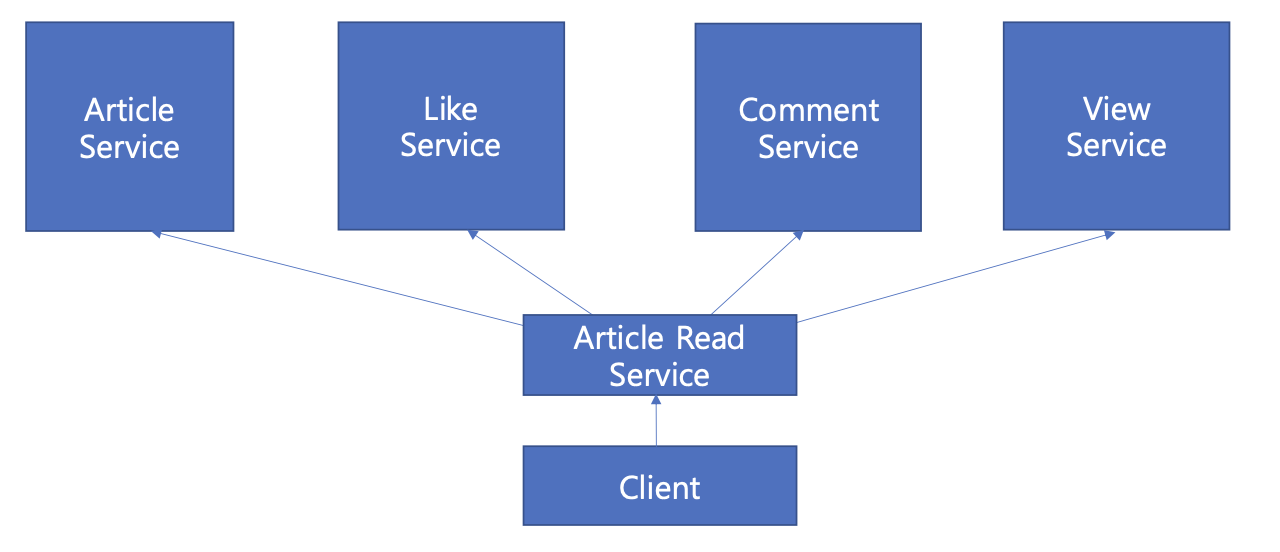
게시글 조회를 위한 서비스를 만들어볼 수 있다. Client는 게시글 조회 서비스로 데이터를 요청하고, 게시글 조회 서비스는 각 마이크로서비스로 개별 데이터를 요청하여 조합 및 응답한다.
이렇게 양방향 의존성을 끊어냄으로써 순환참조 문제가 해결되기 때문에, 각 마이크로서비스는 다시 독립적으로 관리될 수 있다. 또, 게시글 조회를 위한 마이크로서비스이기 때문에, 읽기 트래픽에 대해서만 독립적으로 확장될 수 있다.
문제는 해결된 것으로 보인다.
하지만 위 구조로도 정말 충분할까? 위 구조에서도 몇 가지 낭비되는 지점을 찾을 수 있다.
조회 서비스를 띄워서 의존성을 제거하는 문제는 해결했지만, 각 데이터가 여러 서비스 또는 데이터베이스에 분산되어 있기 때문에, 데이터를 요청하기 위한 네트워크 비용, 각 서비스에 부하 전파, 데이터 조합 및 질의 비용 증가 등의 문제가 발생한다.
이러한 문제를 해결하기 위해? CQRS를 알아보자.
CQRS - Command Query Responsibility Segregation
Command와 Query의 책임을 분리. 데이터에 대한 변경(Command)과 조회(Query) 작업을 구분하는 패턴이다. 클래스 레벨, 패키지 레벨, 서비스 레벨, 데이터 저장소 레벨 같은 좁은 또는 넓은 범위에서 이러한 책임 분리가 일어날 수 있다.
우리 게시판 시스템에 이 개념을 적용해보자.
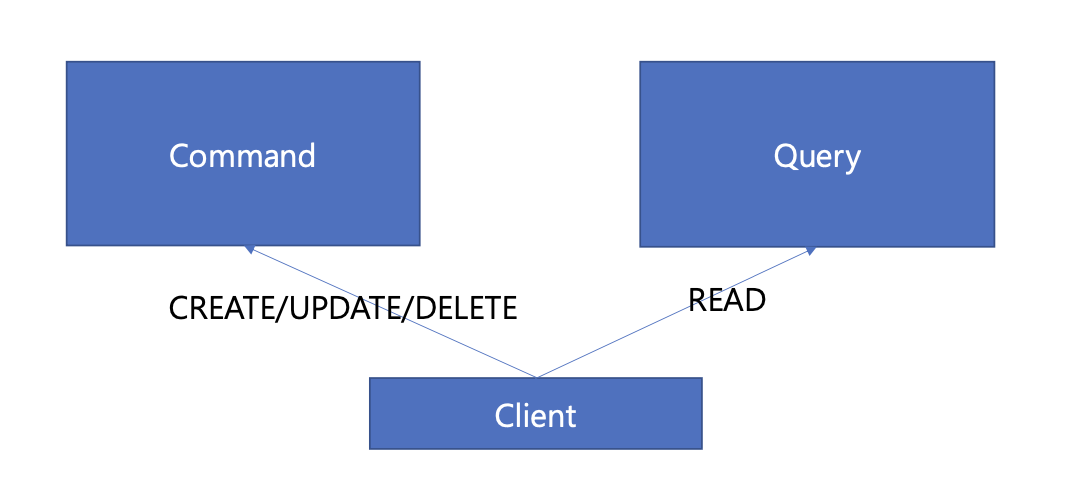
게시글/좋아요/댓글 Command는 기존의 게시글/댓글/좋아요 서비스로, 게시글/좋아요/댓글 Query는 신규로 만드는 게시글 조회 서비스 마이크로서비스 레벨에서 분리하는 것이다.
게시글 조회 서비스는 Command로부터 게시글/댓글/좋아요 데이터를 어떻게 가져올 수 있을까?
Command 서버에서 실시간으로 가져오면, 결국 Command 서버로 부하가 전파되는 문제가 여전히 남아있다. 게시글 조회 서비스에 자체 데이터베이스를 구축하고 데이터를 채워보자. 데이터 저장소 레벨에서 분리하는 것이다.
근데 Query 데이터베이스는 데이터의 실시간 변경 사항을 어떻게 가져올 수 있을까?
API로 주기적으로 변경 사항을 polling 해올 수도 있고, Message Broker를 활용할 수도 있다.
하지만 이전 글에서 카프카 설계 방법에 대해서 알아봤고, 이미 구축 된 메세지 브로커를 사용해보겠다.
https://hwasowl-log.tistory.com/37
대규모 시스템 환경에서의 Kafka Producer 설계 - Transactional Messaging
프로듀서가 카프카에게 이벤트 발행 도중 장애가 발생한다면 어떤 일이 발생할까? 카프카의 모든 브로커 장애가 발생했을 수도, 네트워크 순단일 수도 있다. Producer는 Kafka로의 데이터 전송과 무
hwasowl-log.tistory.com
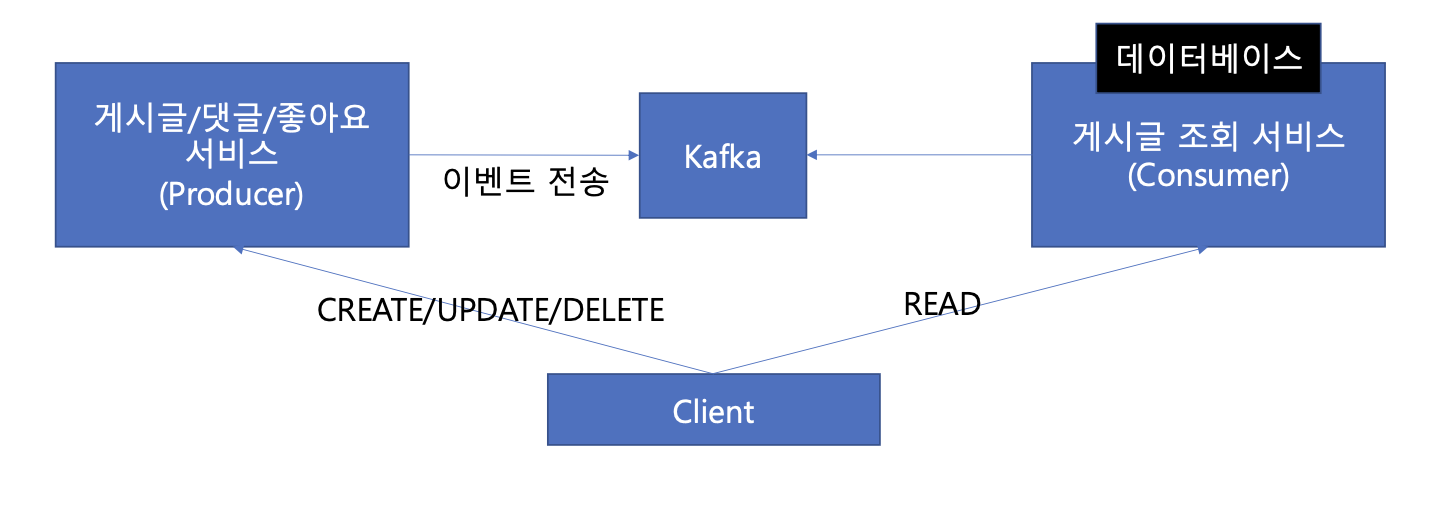
이벤트는 각 프로듀서에서 이미 카프카로 전송하고 있기 때문에, 컨슈머 그룹만 달리해서 그대로 사용한다. 근데 게시글 조회 서비스는, 데이터베이스에서 데이터를 어떻게 관리할 수 있을까? 게시글/댓글/좋아요 서비스의 데이터 모델과 동일하게 관리해야 할까?
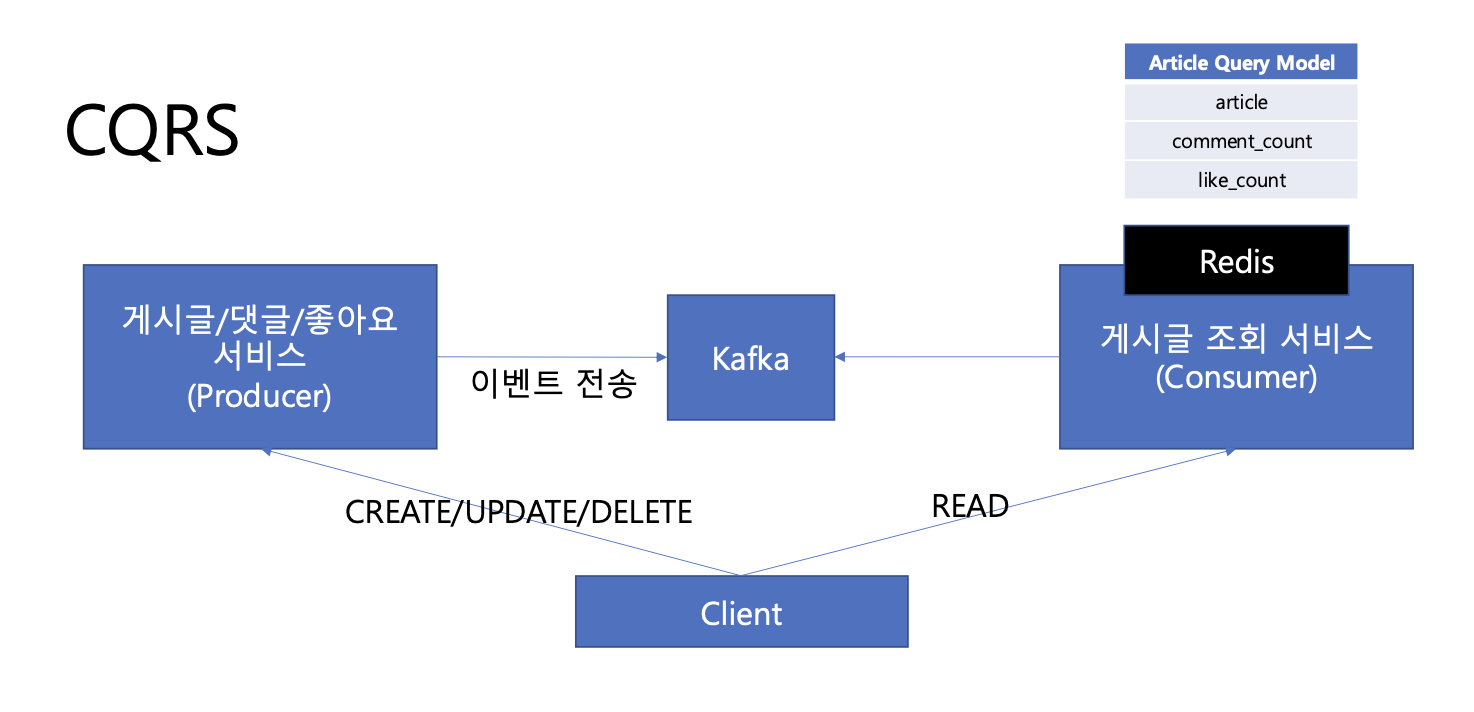
데이터 모델은 반드시 Command 서버와 동일할 필요는 없다. 분산된 데이터를 어차피 조합하여 질의해야 하므로, Query에서는 조인 비용을 줄이고, 조회 최적화를 위해 필요한 데이터가 비정규화된 Query 모델을 만들어보자.
Query Model = 게시글 + 댓글 수 + 좋아요 수 / Query Model 단건만 조회하면, 필요한 데이터를 모두 조회할 수 있다.
그리고 특성상 빠른 성능으로 데이터를 제공하기 위해 레디스를 활용할 수 있다. 하지만 디스크에 비해 용량 대비 가격이 비싸기에 Redis에 TTL(1일)을 설정하여, 24시간 이내의 최신글만 Redis에 보관한다.
근데 만약에 Query 데이터베이스(Redis)에 데이터가 만료되었다면 어떻게 해야 할까?
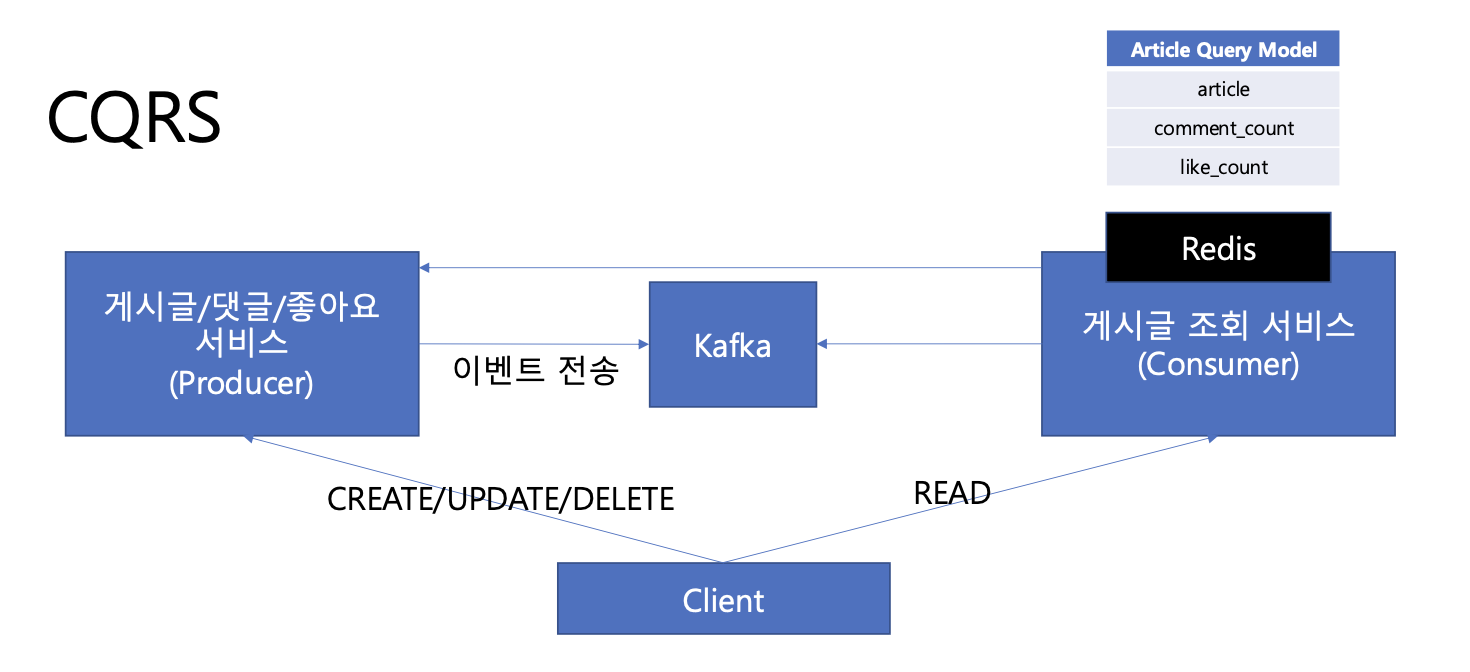
Command 서버로 원본 데이터를 다시 요청하여 Query Model을 만들어볼 수 있다. 만료된 데이터만 간헐적으로 요청하므로, 이러한 트래픽은 크지 않을 것이다. 또한, Query 데이터베이스의 장애 상황, 이벤트 누락, 데이터 유실 등 상황에, 원본 데이터 서버로 질의하여 가용성을 높일 수 있다. 하지만 장애 전파에 대한 위험성은 충분히 고려해야 한다.
'개인프로젝트' 카테고리의 다른 글
| 트랜잭션 전파 옵션 REQUIRES_NEW를 사용해 외부 API 호출을 효율적으로 관리하자 (1) | 2025.09.16 |
|---|---|
| 캐시, 동일 요청 최적화 방법 Request Collapsing (0) | 2025.05.30 |
| Kafka Producer 설계 - Transactional Messaging, Transactional Outbox (0) | 2025.05.28 |
| 동시성 대응 방법 - 비동기 순차처리, 비관적&낙관적 락 (2) | 2025.05.24 |
| 조회 인덱스 최적화 방법 Covering Index (0) | 2025.05.02 |



