
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- transcation outbox
- 특성화고졸재직자후기
- Gabage Collection
- request collapsing
- Shard
- N+1
- session clustering
- session storage
- 일급컬렉션
- 분산 환경 세션 관리
- SpringSecurity
- 전파옵션
- 특성화고졸재직자편입
- 엔티티
- Kafka
- 트랜잭션 격리수준
- 특성화고졸재직자
- sticky session
- 로드밸런서
- 분산트랜잭션
- Scale out
- 서비스장애
- outbox
- Scale Up
- cache
- 트랜잭션
- Fetch Join
- pagnation
- JPA
- recordlock
- Today
- Total
hwasowl.log
fetch join 사용 시 생길 수 있는 문제점 - Pagination 본문
전 글에서는 JPA N+1 문제 해결방안에 대해서 다뤄보았다.
fetch join으로 N+1 문제를 모두 해결할 수 있어 보이지만 사용 시 유의점이 있는 케이스들이 크게 두 가지가 있다. 그 중 하나인 Pagination 문제에 대해서 알아보도록 하자. 예제는 전 글과 동일한 연관관계를 사용하겠다.
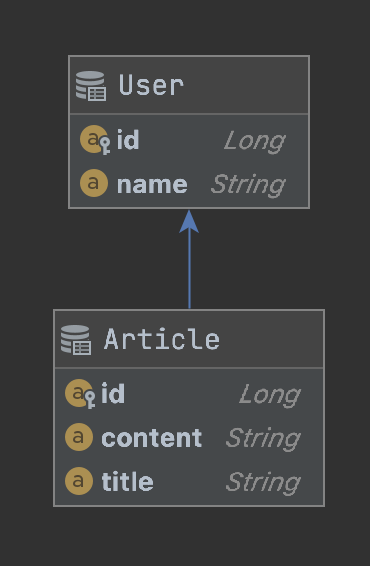
Pagination 이슈
페이징 처리를 JPA에서 할 때 가장 많이 겪는 이슈이다. fetch join을 통해 N+1을 개선한다고는 하지만 막상 Page를 반환하는 쿼리를 작성해보면 다음과 같은 에러가 발생하기 때문이다.
@EntityGraph(attributePaths = {"articles"}, type = EntityGraphType.FETCH)
@Query("select distinct u from User u left join u.articles")
Page<User> findAllPage(Pageable pageable);
@Test
@DisplayName("fetch join을 paging처리에서 사용해도 N+1문제가 발생한다.")
void pagingFetchJoinTest() {
System.out.println("== start ==");
PageRequest pageRequest = PageRequest.of(0, 2);
Page<User> users = userRepository.findAllPage(pageRequest);
System.out.println("== find all ==");
for (User user : users) {
System.out.println(user.articles().size());
}
}
0페이지에서 2명의 유저를 반환하는 PageRequest 객체를 파라미터로 입력받았다. 과연 정상적으로 쿼리가 하나만 나갈까?
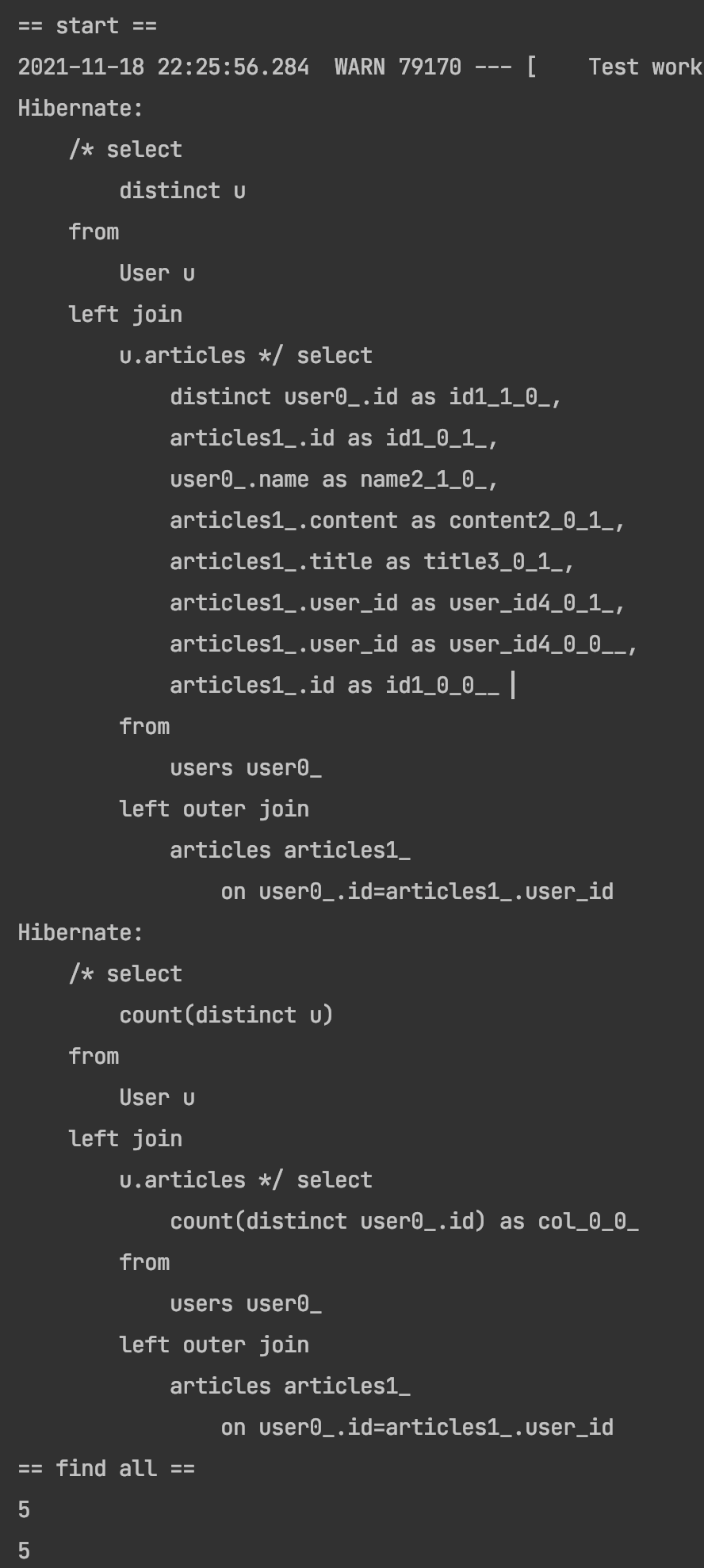
로그를 보면 하나만 나가긴 했다. (카운트는 페이지 반환 시 무조건 발생하는 쿼리이므로 무시하겠다)
쿼리를 자세히보면 MySQL에서 페이징 처리를 할 때 사용하는 Limit, Offset이 없다. 분명 Request를 만들 때 지정을 해줬는데도 말이다. 근데 또 반환 값은 2명의 유저 article 사이즈가 나왔는데 뭐가 어떻게 된걸까?
이미지에서 잘려서 안보이겠지만 ==start== 밑에 어떠한 WARN 구문이 있다.
WARN 79170 --- [ Test worker] o.h.h.internal.ast.QueryTranslatorImpl : HHH000104: firstResult/maxResults specified with collection fetch; applying in memory!
해석해보면 collection fetch에 대해서 페이징처리가 나왔긴 한데 applying in memory, 즉 인메모리를 적용해 조인을 했다고 한다.
실제 날아간 쿼리와 이 문구를 통합해서 이해를 해보면 일단 List의 모든 값을 select해서 인메모리에 저장하고, application 단에서 필요한 페이지만큼 반환을 알아서 해주었다는 이야기가 된다.
이러면 우리는 사실상 페이징을 한 이유가 없어지는 것과 마찬가지가 된다. 100만건의 데이터가 있을 때 10건의 데이터만 페이징을 하고 싶었으나 100만건을 다 가져온다? 그것도 메모리에 저장해서? OOM(Out of Memory)이 발생할 확률이 매우 높다.
따라서 페이지네이션에서는 fetch join을 하고 싶어서 한다 하더라도 해결을 할 수 없다.
1. Pagination 해결책 - ToOne 관계에서의 페이징 처리
~ToOne 관계라면 페이징 처리를 진행해도 유효하다.
@EntityGraph(attributePaths = {"user"}, type = EntityGraphType.FETCH)
@Query("select a from Article a left join a.user")
Page<Article> findAllPage(Pageable pageable);
article 은 유저에 대해서 ManyToOne 연관관계이기 때문에 지금처럼 페이지네이션을 진행한다고 해도 인메모리에서 모든 article을 조회하는 것이 아닌 limit을 걸어 필요한 데이터만 가져올 수 있다.
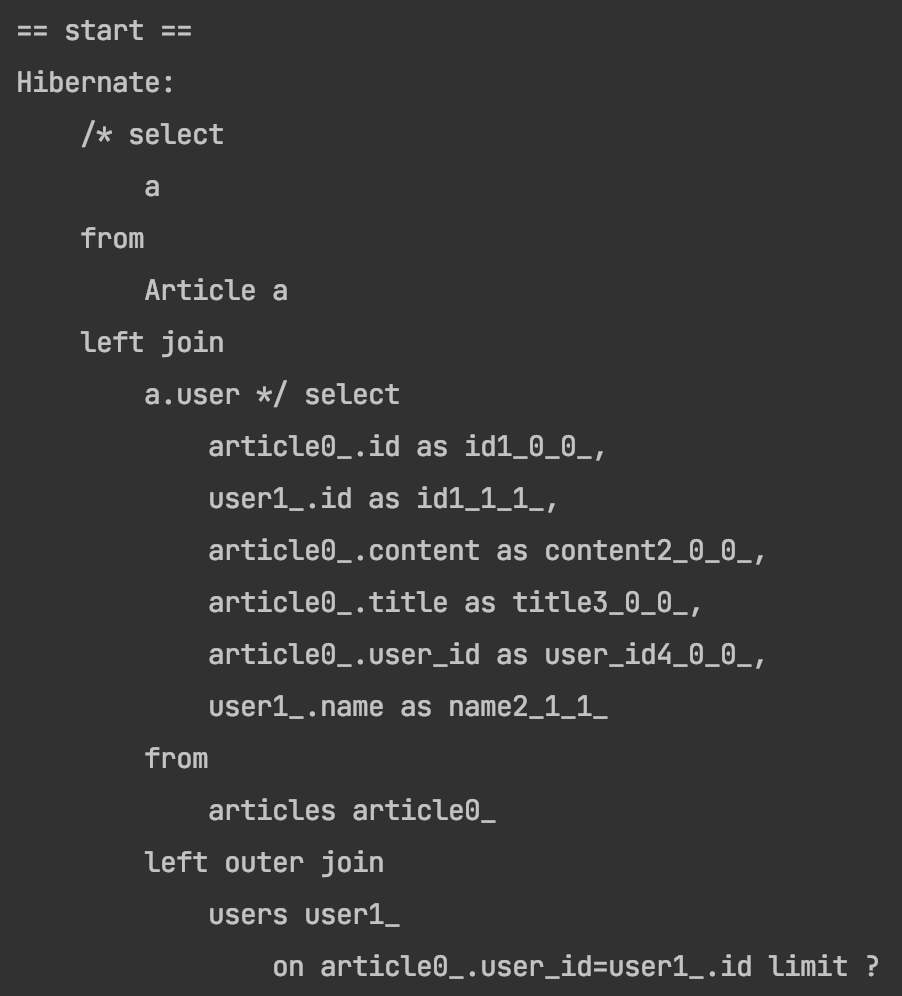
~ToOne 관계에 있는 경우 fetch join을 걸어도 페이지네이션이 의도한대로 제공된다는 것을 알면 좋을 것 같다.
2. Pagination 해결책 - Batch Size
~ToMany 즉 컬랙션 조인을 했을 경우 Many인 다객체들이 One에 매핑되어 fetch join된다면 페이지네이션에서 객수를 판단하기 힘들기 때문에 임의로 인메모리에서 조정한다고 얘기했었다.
따라서 컬랙션을 조인을 해야 하는 경우 fetch join을 아예 사용하지 않고 조회할 컬랙션 필드에 대해서 @BatchSIze 를 걸어 해결한다.
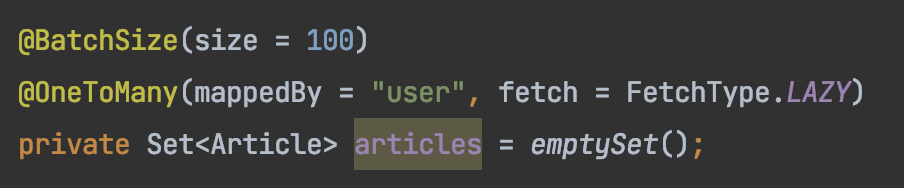
이렇게 설정하고 동일한 테스트 코드를 날리면 article만 따로 한번에 select하게 된다. 처음 지연로딩 default한 설정 + 페이지네이션은 어떻게 처리되는지 결과를 한번 보자

분명 User에 대해서 limit 쿼리가 나갔기 때문에 인메모리가 아닌 정상적인 pagination이 작동되었는데 밑에 article을 select하는 쿼리가 하나 등장했다.
그 이유는 지연로딩하는 객체에 대해서 배치성 로딩을 하는 것 이라고 생각하면 된다.
기존 지연로딩에 대해서는 객체를 조회할 때 그때그떄 쿼리문을 날려서 N+1문제가 발생한 반면, 객체를 조회하는 시점에 쿼리를 하나만 날리는게 아니라 해당하는 아티클에 대해서 쿼리를 batch size개 날리는 것이다. 저 batch 쿼리에서 where 부분만 확대해서 보겠다.
where
articles0_.user_id in (
?, ?
)
in (?, ?)이 결국 user id를 100개 가져오는 쿼리문으로써 그때그때 조회하는 것이 아닌 조회할 때 batch size만큼 한번에 가져와서 뒤에 생길 지연에 대해 미리 방지하는 것이라고 보면 좋을 것 같다.
다만, 배치 사이즈는 연관관계에서의 데이터 사이즈를 확실하게 알 수만 있다면 최적화된 크기를 구할 수 있지만, 사실 일반적인 현업 케이스에서 최적화된 데이터 케이스를 알기는 힘들고 일반적으로 100~1000을 쓴다이지 확실하게 알지 못한다면 좋지 못한 방법이 될 수 있다.
3. Pagination 해결책 - @Fetch(FetchMode.SUBSELECT)
@BatchSize와 비슷하지만 다른 어노테이션이다.
@BatchSize의 경우 사이즈 객수 제한을 임의로 두어서 사용자가 최적화된 데이터 사이즈를 적용하게끔 도와준다면 이 어노테이션은 그냥 다 가져온다 (select all)
코드 결과를 바로 보겠다.
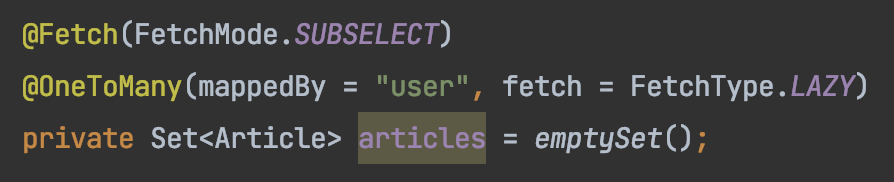
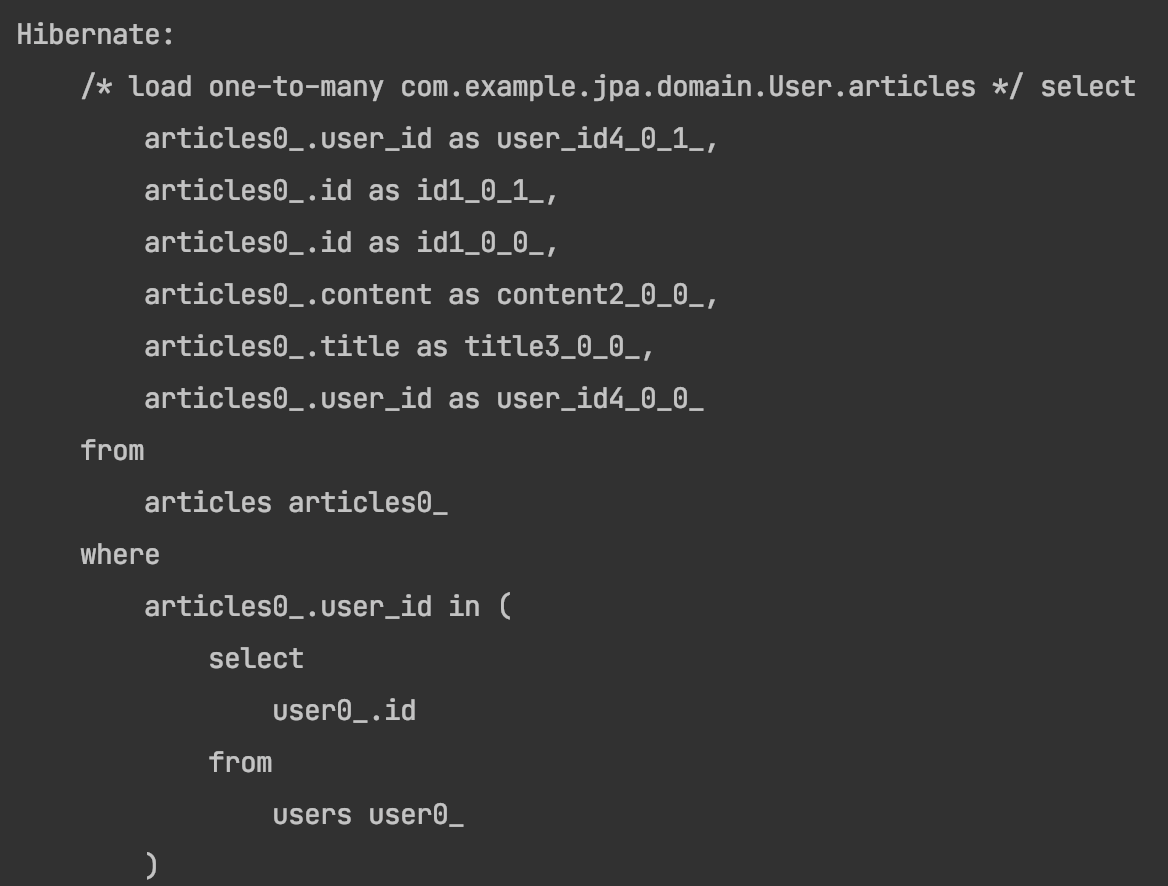
다른 부분은 배치사이즈와 동일하니 컬렉션을 조회하는 쿼리만 가져왔다. 보면 where절 안에 in 문에서 현재 select할 user의 아이디가 들어가있어야 하는데 유저를 전부 가져오는 select all 쿼리가 들어있음을 알 수 있다.
즉 @BatchSize의 경우는 설정한 size만큼만 user id를 입력해 그때그때 프록시 상태에 따라 지연로딩을 했다면, 지금은 그런거 없어 모든 user id를 조회해오겠다는 뜻이다.
다만 한번에 모든 배치를 가져오는 것이 좋은 판단인가? 하는 의문이 있다. 배치 사이즈의 경우 100일때 100만명에 유저에서 100명의 유저 id에 대한 검색을 하는 반면, subselect는 100만명 모두를 일단 select all 해오기 때문이다.
정리
대용량 데이터를 가져와야 하거나 메모리 상황에 제약이 있는 상황이라면 사이즈만큼 줄여서 가져오는 @BatchSize를 사용하는 것이 OOM도 방지해주고 꽤 유효한 선택이 될 것 같다. 소량의 데이터를 불러와야 하는 상황이라면 SubSelect를 사용해서 나가는 쿼리를 줄이는 것이 유효할 것 같다는 생각이 든다.
[이어서 다른 문제점을 다룬 글]
둘 이상의 컬렉션 조인 시 생길 수 있는 문제점 - MultipleBagFetchException
'기술면접' 카테고리의 다른 글
| 둘 이상의 컬렉션 조인 시 생길 수 있는 문제점 - MultipleBagFetchException (0) | 2024.12.02 |
|---|---|
| JPA N+1 (0) | 2024.11.30 |
| 트랜잭션 격리수준 (0) | 2024.11.26 |


